

DeepSeek-R1 et DeepSeek-V3 ont fait sensation dans le monde entier depuis leur lancement en open source.
Ils sont un cadeau de l'équipe de DeepSeek à toute l'humanité, et nous sommes sincèrement heureux de leur succès.
Après des jours de travail acharné de la part des équipes de Silicon Mobility et de Huawei Cloud, nous offrons aujourd'hui aux utilisateurs chinois un cadeau pour le Nouvel An chinois : la plateforme de services en nuage à grande échelle SiliconCloud a lancé DeepSeek-V3 et DeepSeek-R1, qui sont basés sur le service en nuage Ascend de Huawei Cloud.
Il convient de souligner que nous avons reçu un grand soutien de la part de DeepSeek et de Huawei Cloud, tant pour l'adaptation de DeepSeek-R1 & V3 sur Ascend que pour le processus de lancement d'autres modèles précédemment, et nous tenons à exprimer notre profonde gratitude et notre grand respect.
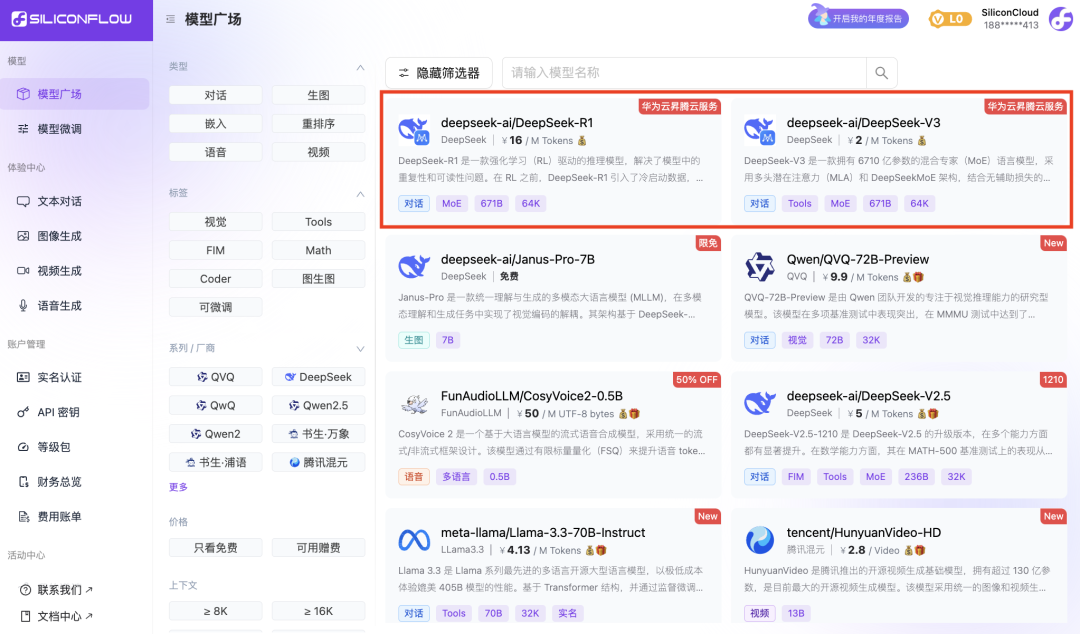
Caractéristiques
Ces deux modèles lancés par SiliconCloud comprennent principalement cinq caractéristiques majeures :
Basé sur le service cloud Ascend de Huawei Cloud, nous avons lancé le service cloud Ascend de Huawei Cloud. DeepSeek x Silicon Mobility x Huawei Cloud R1 & V3 model inference service pour la première fois.
Grâce à l'innovation conjointe entre les deux parties, et avec le soutien du moteur d'accélération d'inférence auto-développé, le modèle DeepSeek déployé par l'équipe de Silicon Mobility sur la base du service cloud Ascend de Huawei Cloud peut atteindre le même effet qu'un modèle de déploiement de GPU haut de gamme dans le monde.
Fournir des services d'inférence DeepSeek-R1 et V3 stables au niveau de la production. Cela permet aux développeurs de fonctionner de manière stable dans des environnements de production à grande échelle et de répondre aux besoins de déploiement commercial. Les services Huawei Cloud Ascend AI fournissent une puissance de calcul abondante, élastique et suffisante.
Il n'y a pas de seuil de déploiement, ce qui permet aux développeurs de se concentrer sur le développement d'applications. Lorsqu'ils développent des applications, ils peuvent appeler directement l'API SiliconCloud, ce qui offre une expérience plus facile et plus conviviale.
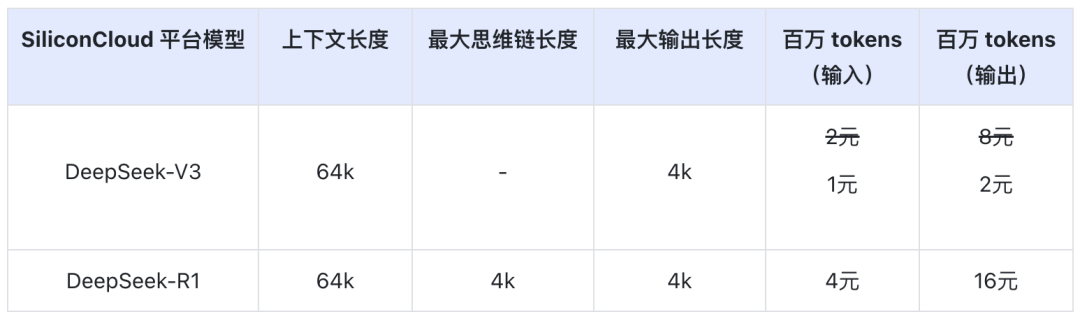
Le prix du DeepSeek-V3 sur SiliconCloud pendant la période de remise officielle (jusqu'à 24h00 le 8 février) est de 1¥ / M tokens (entrée) & 2¥ / M tokens (sortie), et le prix du DeepSeek-R1 est de 4¥ / M tokens (entrée) & 16¥ / M tokens (sortie).
Expérience en ligne
DeepSeek-R1 avec SiliconCloud
DeepSeek-V3 avec SiliconCloud
Documentation de l'API
Les développeurs peuvent expérimenter l'effet de DeepSeek-R1 & V3 accéléré sur les puces nationales sur SiliconCloud. La vitesse de sortie plus rapide est toujours en cours d'optimisation.


Expérience dans l'application client
Si vous souhaitez expérimenter le modèle DeepSeek-R1 & V3 directement dans l'application client, vous pouvez installer les produits suivants localement et accéder à l'API SiliconCloud (vous pouvez personnaliser et ajouter ces deux modèles) pour expérimenter DeepSeek-R1 & V3.
- Applications clients de grands modèles : ChatBox, Cherry Studio, OneAPI, LobeChat, NextChat
- Applications de génération de code : CurseurPlanche à voile, Cline
- Plate-forme de développement d'applications à grand modèle :Dify
- Base de connaissances sur l'IA :Obsidian AIetFastGPT
- Plug-in de traduction :Immersive Translate et Eurodict
Pour plus de tutoriels d'accès aux scénarios et aux cas d'application, veuillez vous référer à ici
Token Factory SiliconCloud
Qwen2.5 (7B), etc. Plus de 20 modèles libres d'utilisation
En tant que plateforme de services en nuage à guichet unique pour les grands modèles, SiliconCloud s'engage à fournir aux développeurs des API de modèles ultra-réactives, abordables, complètes et d'une grande fluidité.
Outre DeepSeek-R1 et DeepSeek-V3, SiliconCloud a également lancé Janus-Pro-7B, CosyVoice2, QVQ-72B-Preview, DeepSeek-VL2, DeepSeek-V2.5-1210, Llama-3.3-70B-Instruct, HunyuanVideo, fish-speech-1.5, Qwen2.5 -7B/14B/32B/72B, FLUX.1, InternLM2.5-20B-Chat, BCE, BGE, SenseVoice-Small, GLM-4-9B-Chat,
des dizaines de modèles linguistiques, de modèles de génération d'images/vidéos, de modèles vocaux, de modèles de code/mathématiques et de modèles vectoriels et de réorganisation.
La plateforme permet aux développeurs de comparer et de combiner librement de grands modèles de diverses modalités afin de choisir la meilleure pratique pour votre application d'IA générative.
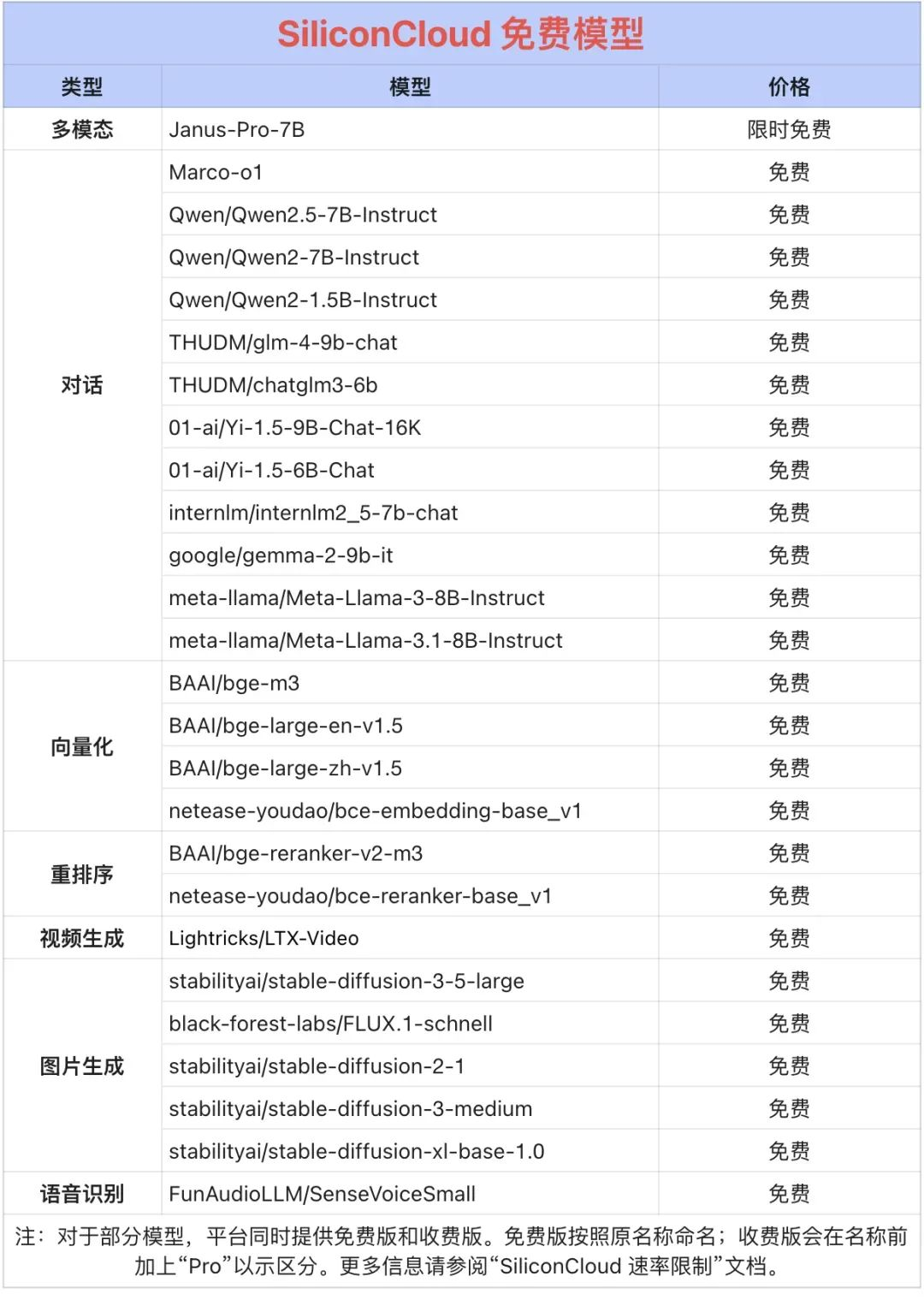
Parmi eux, plus de 20 grands modèles d'API tels que Qwen2.5 (7B) et Llama3.1 (8B) peuvent être utilisés gratuitement, ce qui permet aux développeurs et aux gestionnaires de produits d'atteindre la "liberté des jetons" sans se soucier du coût de la puissance de calcul au cours de la phase de recherche et de développement et de la promotion à grande échelle.




