

DeepSeek-R1 e DeepSeek-V3 hanno fatto scalpore a livello mondiale fin dal loro lancio open source.
Sono un regalo del team DeepSeek a tutta l'umanità e siamo sinceramente felici del loro successo.
Dopo giorni di duro lavoro da parte dei team Silicon Mobility e Huawei Cloud, oggi facciamo un regalo agli utenti cinesi per il Capodanno cinese: la piattaforma di servizi cloud su larga scala SiliconCloud ha lanciato DeepSeek-V3 e DeepSeek-R1, basati sul servizio cloud Ascend di Huawei Cloud.
Va sottolineato che abbiamo ricevuto un grande supporto da DeepSeek e Huawei Cloud, sia nell'adattamento di DeepSeek-R1 & V3 su Ascend che nel processo di lancio di altri modelli in precedenza, e vorremmo esprimere profonda gratitudine e grande rispetto.
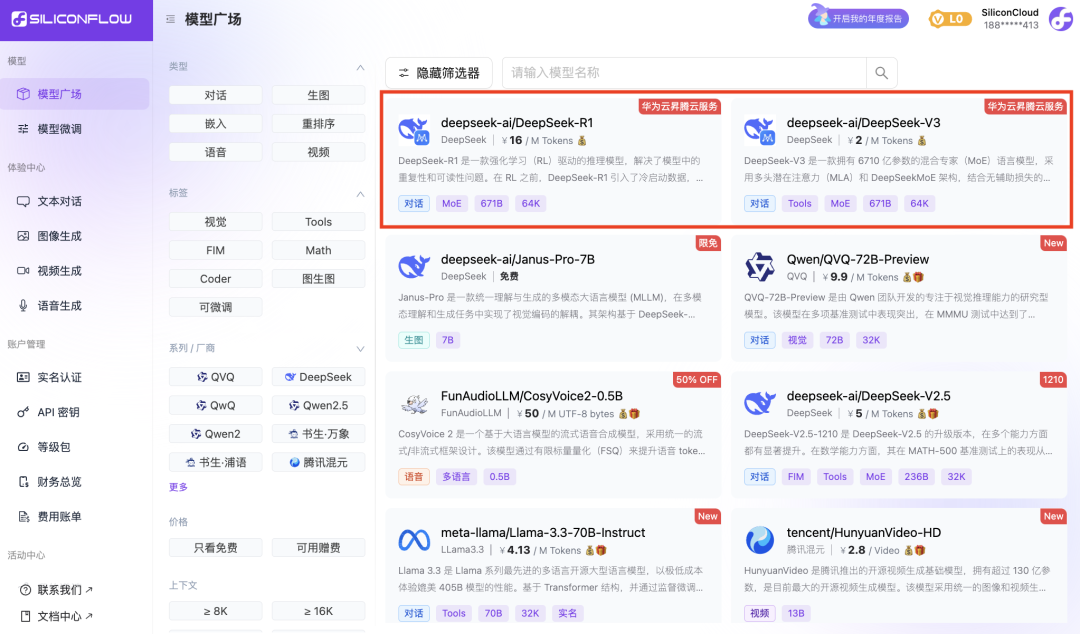
Caratteristiche
Questi due modelli lanciati da SiliconCloud includono principalmente cinque caratteristiche principali:
Sulla base del servizio cloud Ascend di Huawei Cloud, abbiamo lanciato il servizio Ascend. DeepSeek x Silicon Mobility x Huawei Cloud R1 & V3 model inference service per la prima volta.
Grazie all'innovazione congiunta tra le due parti e al supporto del motore di accelerazione dell'inferenza sviluppato in proprio, il modello DeepSeek distribuito dal team di Silicon Mobility sulla base del servizio cloud Ascend di Huawei Cloud può raggiungere lo stesso effetto di un modello di distribuzione di GPU di fascia alta nel mondo.
Fornire servizi di inferenza DeepSeek-R1 e V3 stabili a livello di produzione. Ciò consente agli sviluppatori di funzionare in modo stabile in ambienti di produzione su larga scala e di soddisfare le esigenze di distribuzione commerciale. I servizi Huawei Cloud Ascend AI forniscono una potenza di calcolo abbondante, elastica e sufficiente.
Non c'è alcuna soglia di distribuzione, il che consente agli sviluppatori di concentrarsi maggiormente sullo sviluppo delle applicazioni. Quando sviluppano applicazioni, possono chiamare direttamente l'API di SiliconCloud, che offre un'esperienza più semplice e facile da usare.
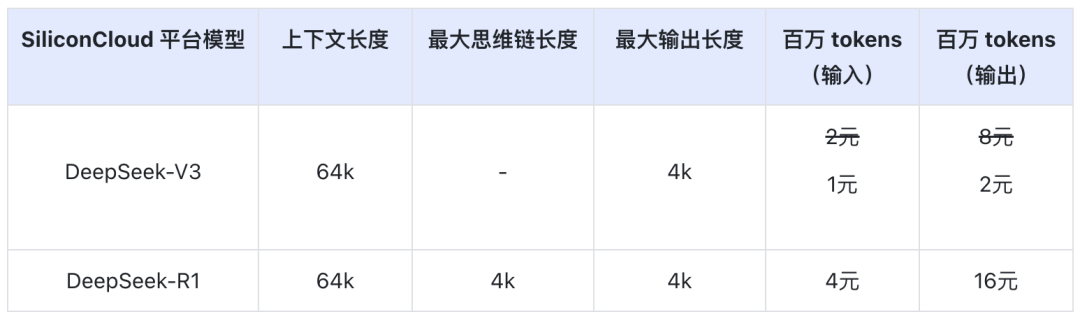
Il prezzo del DeepSeek-V3 su SiliconCloud durante il periodo di sconto ufficiale (fino alle 24:00 dell'8 febbraio) è di ¥1 / M token (input) e ¥2 / M token (output), mentre il prezzo del DeepSeek-R1 è di ¥4 / M token (input) e ¥16 / M token (output).
Esperienza online
DeepSeek-R1 con SiliconCloud
DeepSeek-V3 con SiliconCloud
Documentazione API
Gli sviluppatori possono sperimentare l'effetto di DeepSeek-R1 e V3 accelerato su chip nazionali su SiliconCloud. La velocità di uscita viene continuamente ottimizzata.


Esperienza nell'applicazione client
Se si desidera sperimentare il modello DeepSeek-R1 e V3 direttamente nell'applicazione client, è possibile installare i seguenti prodotti in locale e accedere all'API SiliconCloud (è possibile personalizzare e aggiungere questi due modelli) per sperimentare DeepSeek-R1 e V3.
- Applicazioni client di grande modello: ChatBox, Studio Cherry, OneAPI, LobeChat, NextChat
- Applicazioni per la generazione di codice: Cursore, Windsurf, Cline
- Piattaforma di sviluppo di applicazioni per grandi modelli:Dify
- Base di conoscenza dell'intelligenza artificiale:IA ossidiana, eFastGPT
- Plug-in di traduzione:Immersive Translate, eEurodict
Per ulteriori esercitazioni sull'accesso a scenari e casi applicativi, fare riferimento a qui
Fabbrica di gettoni SiliconCloud
Qwen2.5 (7B), ecc. 20+ modelli utilizzabili gratuitamente
In qualità di piattaforma di servizi cloud one-stop per modelli di grandi dimensioni, SiliconCloud si impegna a fornire agli sviluppatori API per modelli che siano ultra-reattive, convenienti, complete e con un'esperienza fluida come la seta.
Oltre all'DeepSeek-R1 e all'DeepSeek-V3, SiliconCloud ha lanciato anche Janus-Pro-7B, CosyVoice2, QVQ-72B-Preview, DeepSeek-VL2, DeepSeek-V2.5-1210, Llama-3.3-70B-Instruct, HunyuanVideo, fish-speech-1.5, Qwen2.5 -7B/14B/32B/72B, FLUX.1, InternLM2.5-20B-Chat, BCE, BGE, SenseVoice-Small, GLM-4-9B-Chat,
decine di modelli linguistici open source di grandi dimensioni, modelli di generazione di immagini/video, modelli vocali, modelli di codice/matematica e modelli vettoriali e di riordino.
La piattaforma consente agli sviluppatori di confrontare e combinare liberamente modelli di grandi dimensioni di varie modalità per scegliere la pratica migliore per la propria applicazione di IA generativa.
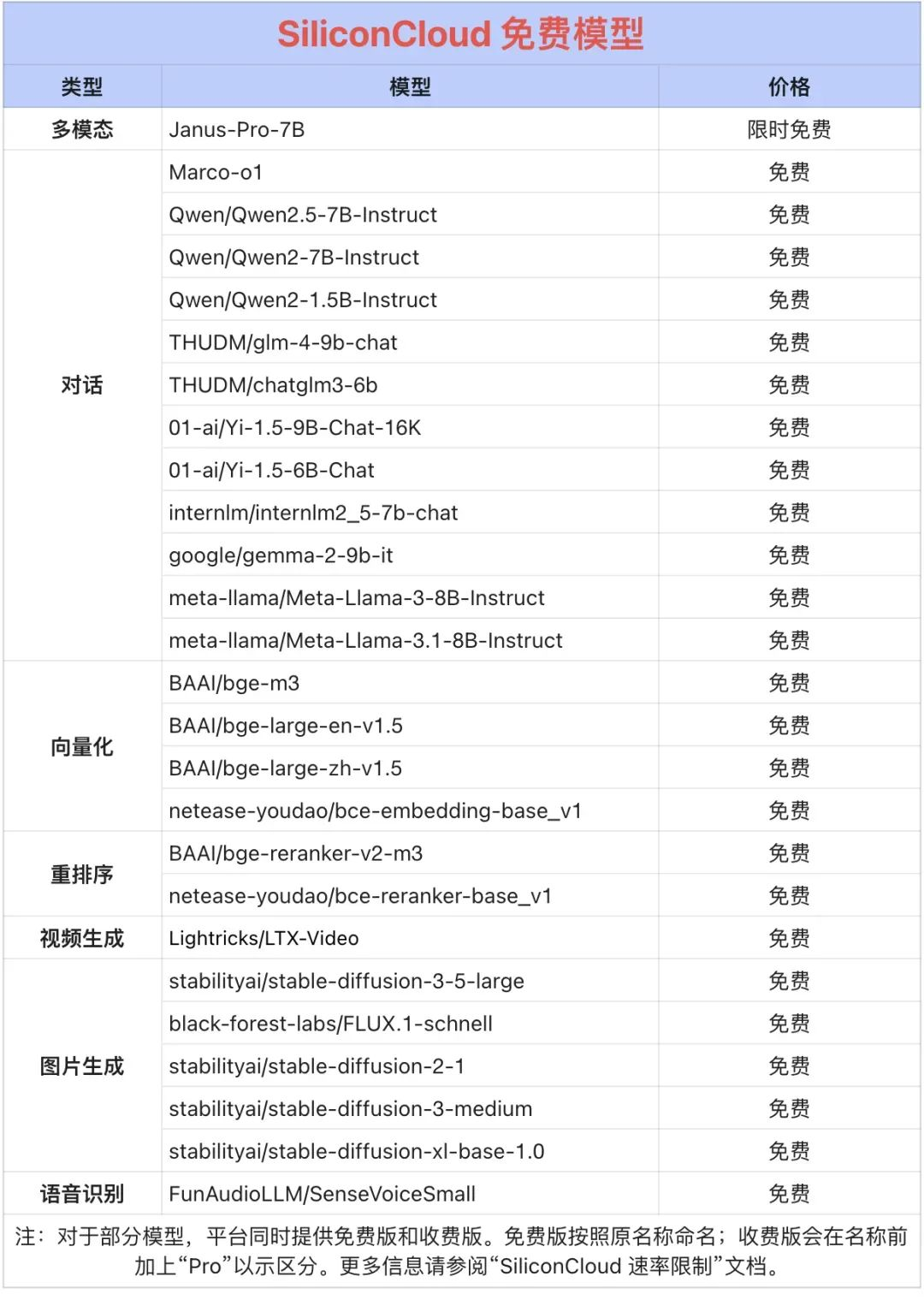
Tra queste, oltre 20 API di modelli di grandi dimensioni come Qwen2.5 (7B) e Llama3.1 (8B) sono di libero utilizzo, consentendo agli sviluppatori e ai responsabili di prodotto di ottenere la "libertà dei token" senza preoccuparsi del costo della potenza di calcolo durante la fase di ricerca e sviluppo e di promozione su larga scala.

