

A história de Gêmeosneu 2.0 está acelerando.
A versão experimental do Flash Thinking em dezembro trouxe aos desenvolvedores um modelo funcional com baixa latência e alto desempenho.
No início deste ano, o Flash Thinking Experimental 2.0 foi atualizado no Google AI Studio para melhorar ainda mais o desempenho, combinando a velocidade do Flash com recursos de inferência aprimorados.
Na semana passada, a versão atualizada 2.0 do Flash foi totalmente lançada nos aplicativos móveis e de desktop do Gemini.
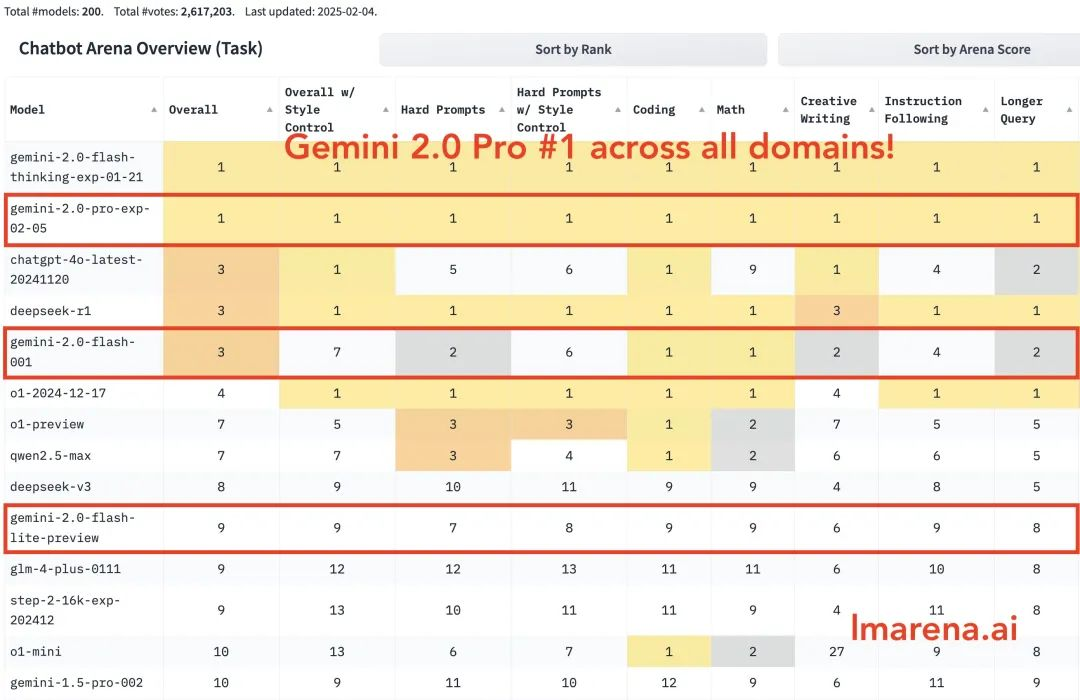
Hoje, três novos membros foram revelados ao mesmo tempo: a versão experimental do Gemini 2.0 Pro, que até agora teve o melhor desempenho em codificação e prompts complexos, o econômico 2.0 Flash-Lite e a versão aprimorada para raciocínio lógico 2.0 Flash Thinking.
Gemini 2.0 Pro está em primeiro lugar em todas as categorias. Gemini-2.0-Flash está entre os três primeiros em codificação, matemática e quebra-cabeças. Flash-lite está entre os dez primeiros em todas as categorias.

Um gráfico de comparação das habilidades dos três modelos:
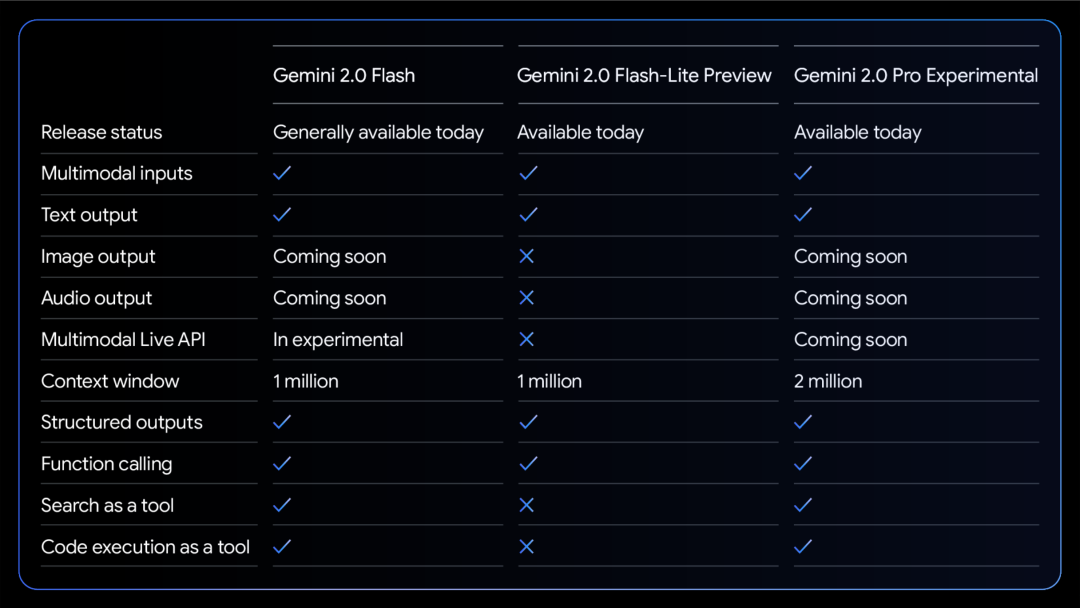
Todos os modelos suportam entrada e saída de texto multimodal.
Mais habilidades modais estão a caminho. Gráfico de força do modelo na área de codificação
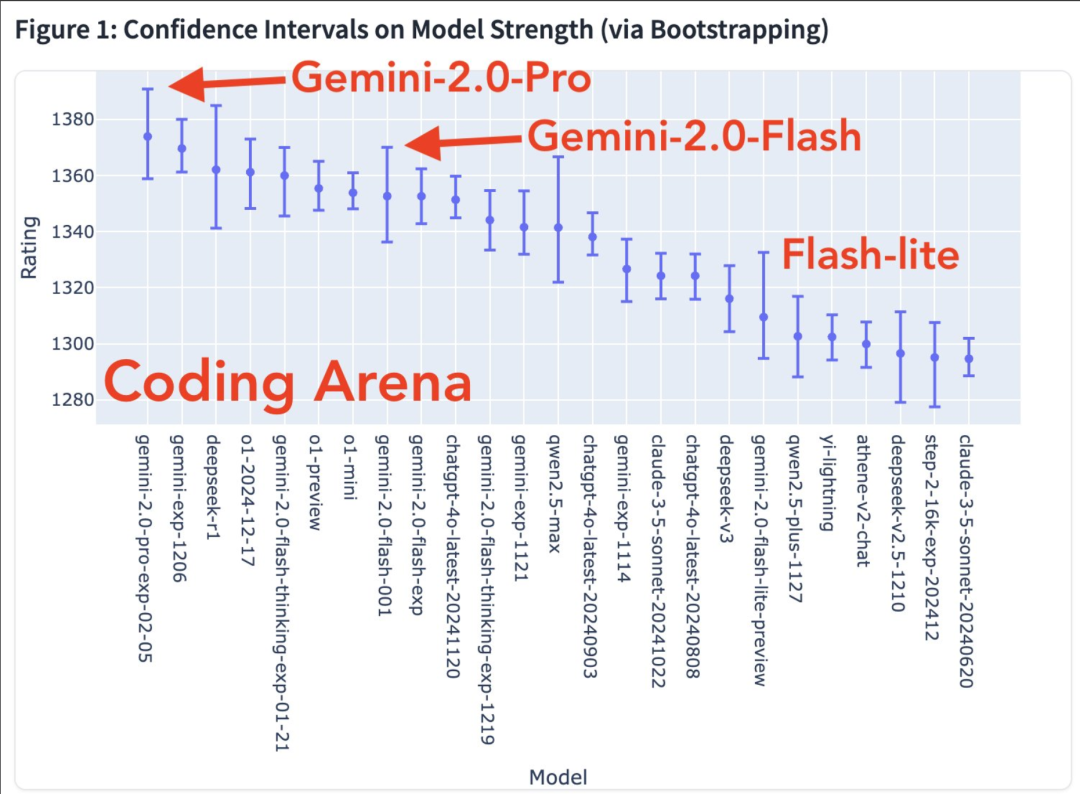
Mapa de calor da taxa de vitória

O Google trata os usuários gratuitos melhor do que o OpenAI trata os usuários Plus. Acesso gratuito ao Gemini 2.0 Pro Experimental no AI Studio:
O serviço Deepseek sempre exibe um erro de espera… Lembre-se de que o primeiro modelo livre de inferência também foi o Flash Thinking 2.0, que foi usado no Google aistudio.
Além disso, há o versão web do Gemini:
Há também um modelo de inferência conectado (então por que separá-lo…)

O Google lançou a versão experimental do Gemini 2.0 Pro, e a melhoria nos testes de benchmark oficiais é bastante impressionante.

Ele tem os recursos de codificação mais poderosos e a capacidade de processar solicitações complexas, além de ter uma melhor capacidade de entender e raciocinar sobre o conhecimento do mundo do que qualquer modelo lançado pelo Google até agora.
Ele tem a maior janela de contexto (200k, e meu contexto longo é uma vantagem relativamente grande do modelo Gemini), o que lhe permite analisar e entender de forma abrangente uma grande quantidade de informações e chamar ferramentas como a pesquisa do Google e a execução de código.
No teste de MATH, ele alcançou 91,81 TP11T, um aumento de cerca de 5 pontos percentuais em relação à versão 1.5. A capacidade de raciocínio do GPQA atingiu 64,71 TP11T, e o teste de conhecimento de mundo do SimpleQA chegou a 44,31 TP11T.
O mais notável é a capacidade de programação. Ele atingiu 36,0% no teste LiveCodeBench, e a precisão da conversão Bird-SQL excedeu 59,3%. Juntamente com a janela de contexto supergrande de 2 milhões de tokens, é o suficiente para lidar com as tarefas de análise de código mais complexas.

Você pode experimentar no cursor.
A capacidade de compreensão multilíngue também é impressionante, com uma pontuação de teste Global MMLU de 86,5%. A compreensão de imagem MMMU é 72,7%, e a capacidade de análise de vídeo é 71,9%.
Gemini 2.0 Flash-Lite é um equilíbrio interessante.
Ele mantém a velocidade e o custo de 1,5 Flash, mas traz melhor desempenho. A janela de contexto com 1 milhão de tokens permite que ele processe mais informações.
O mais prático é sua relação preço/desempenho: a geração de legendas para 40.000 fotos custa menos que $1. Isso torna a IA mais pé no chão.

O blogueiro Shrivastava mencionou: A codificação do Gemini 2.0 Pro é uma loucura!
Dica: use Three.js para criar uma simulação do sistema solar. Adicione uma escala de tempo, um menu suspenso de foco, mostre órbitas e mostre rótulos. Crie tudo em um arquivo para que eu possa colá-lo em um editor online e visualizar a saída.

Além disso, alguns usuários mencionaram que o Gemini 2.0 Flash produziu melhores resultados em um de seus próprios testes de paradoxo:

Por fim, o Google mencionou que a segurança do Gemini 2.0, não apenas o patch, está no centro do design desde o início.
Deixe o modelo aprender a ser autocrítico. Use o aprendizado por reforço para deixar o Gemini avaliar suas próprias respostas e fornecer feedback mais preciso. Isso o torna mais robusto ao lidar com tópicos sensíveis.
O teste automatizado da equipe vermelha é interessante. Ele é projetado especificamente para evitar a injeção de palavras de prompt indiretas, o que é como equipar a IA com um sistema imunológico para evitar que alguém esconda comandos maliciosos nos dados.


