

DeepSeek-R1 und DeepSeek-V3 haben seit ihrer Open-Source-Einführung weltweit für Aufsehen gesorgt.
Sie sind ein Geschenk des DeepSeek-Teams an die gesamte Menschheit, und wir freuen uns aufrichtig über ihren Erfolg.
Nach tagelanger harter Arbeit der Silicon Mobility- und Huawei Cloud-Teams machen wir heute auch chinesischen Nutzern ein Geschenk zum chinesischen Neujahr: Die groß angelegte Cloud-Service-Plattform SiliconCloud hat DeepSeek-V3 und DeepSeek-R1 auf den Markt gebracht, die auf dem Cloud-Service Ascend von Huawei Cloud basieren.
Es sollte betont werden, dass wir große Unterstützung von DeepSeek und Huawei Cloud erhalten haben, sowohl bei der Anpassung von DeepSeek-R1 & V3 auf Ascend als auch bei der Markteinführung anderer Modelle zuvor, und wir möchten tiefe Dankbarkeit und hohen Respekt aussprechen.
Eigenschaften
Diese beiden von SiliconCloud eingeführten Modelle umfassen im Wesentlichen fünf Hauptmerkmale:
Auf der Grundlage des Cloud-Dienstes Ascend von Huawei Cloud haben wir die DeepSeek x Silicon Mobility x Huawei Cloud R1 & V3 Modellinferenzdienst zum ersten Mal.
Durch die gemeinsame Innovation der beiden Parteien und mit Unterstützung der selbst entwickelten Inferenzbeschleunigungs-Engine kann das DeepSeek-Modell, das vom Silicon Mobility-Team auf der Grundlage des Ascend-Cloud-Services von Huawei Cloud eingesetzt wird, die gleiche Wirkung erzielen wie ein High-End-GPU-Einsatzmodell in der Welt.
Bereitstellung von stabilen DeepSeek-R1- und V3-Inferenzdiensten auf Produktionsebene. Dies ermöglicht Entwicklern eine stabile Ausführung in groß angelegten Produktionsumgebungen und erfüllt die Anforderungen der kommerziellen Bereitstellung. Die Huawei Cloud Ascend AI-Services bieten reichlich, elastische und ausreichende Rechenleistung.
Es gibt keine Bereitstellungsschwelle, so dass sich die Entwickler mehr auf die Anwendungsentwicklung konzentrieren können. Bei der Entwicklung von Anwendungen können sie direkt die SiliconCloud-API aufrufen, was eine einfachere und benutzerfreundlichere Erfahrung bietet.
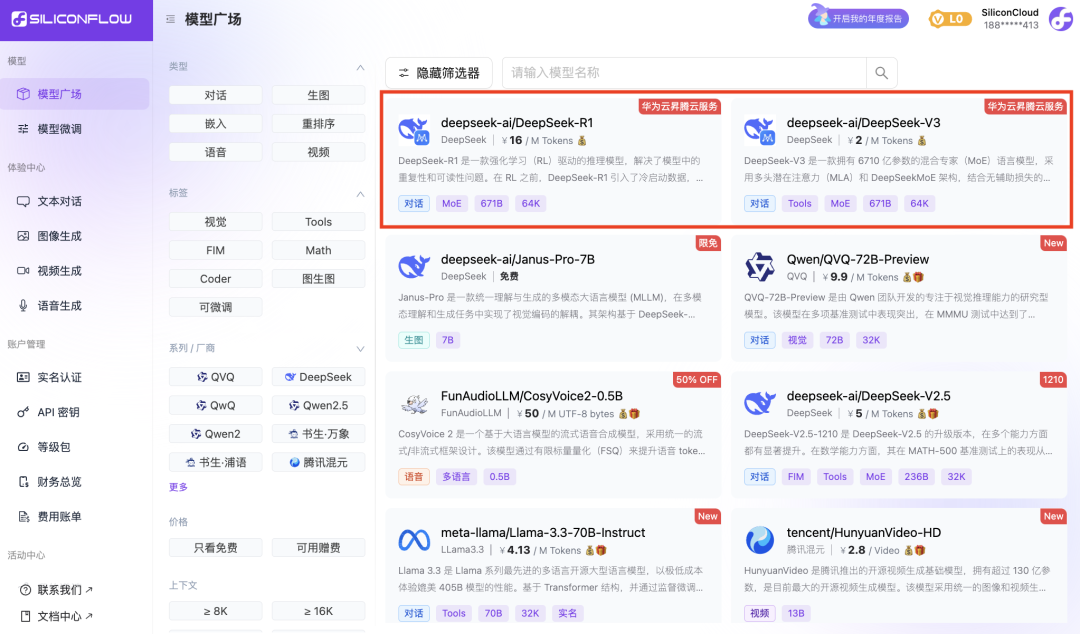
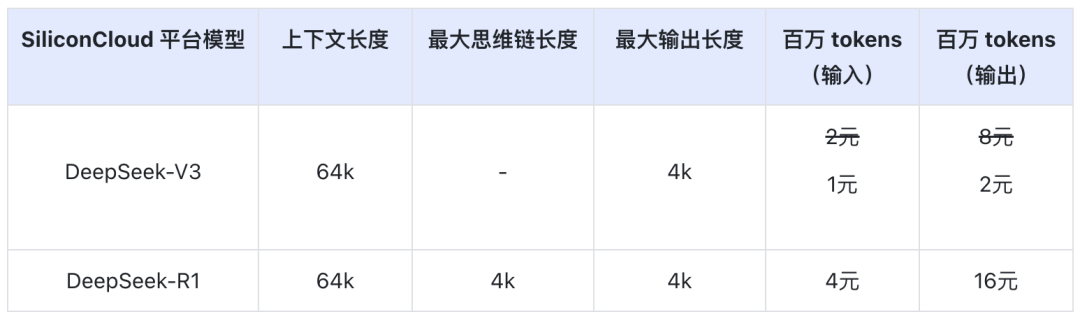
Der DeepSeek-V3 Preis auf SiliconCloud während der offiziellen Rabattperiode (bis 24:00 am 8. Februar) beträgt ¥1 / M Token (Input) & ¥2 / M Token (Output), und der DeepSeek-R1 Preis beträgt ¥4 / M Token (Input) & ¥16 / M Token (Output).
Online-Erfahrung
DeepSeek-R1 mit SiliconCloud
DeepSeek-V3 mit SiliconCloud
API-Dokumentation
Entwickler können den Effekt von DeepSeek-R1 & V3 beschleunigt auf heimischen Chips auf SiliconCloud erleben. Die schnellere Ausgabegeschwindigkeit wird weiterhin kontinuierlich optimiert.


Erfahrung mit Client-Anwendungen
Wenn Sie das Modell DeepSeek-R1 & V3 direkt in der Client-Anwendung erleben möchten, können Sie die folgenden Produkte lokal installieren und auf die SiliconCloud-API zugreifen (Sie können diese beiden Modelle anpassen und hinzufügen), um DeepSeek-R1 & V3 zu erleben.
- Große Modell-Client-Anwendungen: ChatBox, Studio Kirsche, OneAPI, LobeChat, NextChat
- Anwendungen zur Codegenerierung: Cursor, Windsurfen, Cline
- Entwicklungsplattform für große Modellanwendungen:Dify
- AI-Wissensbasis:Obsidian-KIundFastGPT
- Übersetzungs-Plugin:Immersive Translate, undEurodict
Weitere Tutorials für den Zugang zu Szenarien und Anwendungsfällen finden Sie unter hier
Token-Fabrik SiliconCloud
Qwen2.5 (7B), etc. 20+ Modelle zur freien Verwendung
Als One-Stop-Cloud-Service-Plattform für große Modelle hat sich SiliconCloud zum Ziel gesetzt, Entwicklern Modell-APIs zur Verfügung zu stellen, die extrem reaktionsschnell, erschwinglich und umfassend sind und eine reibungslose Nutzung ermöglichen.
Zusätzlich zu DeepSeek-R1 und DeepSeek-V3 hat SiliconCloud auch Janus-Pro-7B, CosyVoice2, QVQ-72B-Preview, DeepSeek-VL2, DeepSeek-V2.5-1210, Llama-3.3-70B-Instruct, HunyuanVideo, fish-speech-1.5, Qwen2.5 -7B/14B/32B/72B, FLUX.1, InternLM2.5-20B-Chat, BCE, BGE, SenseVoice-Small, GLM-4-9B-Chat,
Dutzende von quelloffenen großen Sprachmodellen, Bild-/Videoerzeugungsmodellen, Sprachmodellen, Code-/Mathe-Modellen sowie Vektor- und Neuordnungsmodellen.
Die Plattform ermöglicht es Entwicklern, große Modelle verschiedener Modalitäten frei zu vergleichen und zu kombinieren, um das beste Verfahren für ihre generative KI-Anwendung auszuwählen.
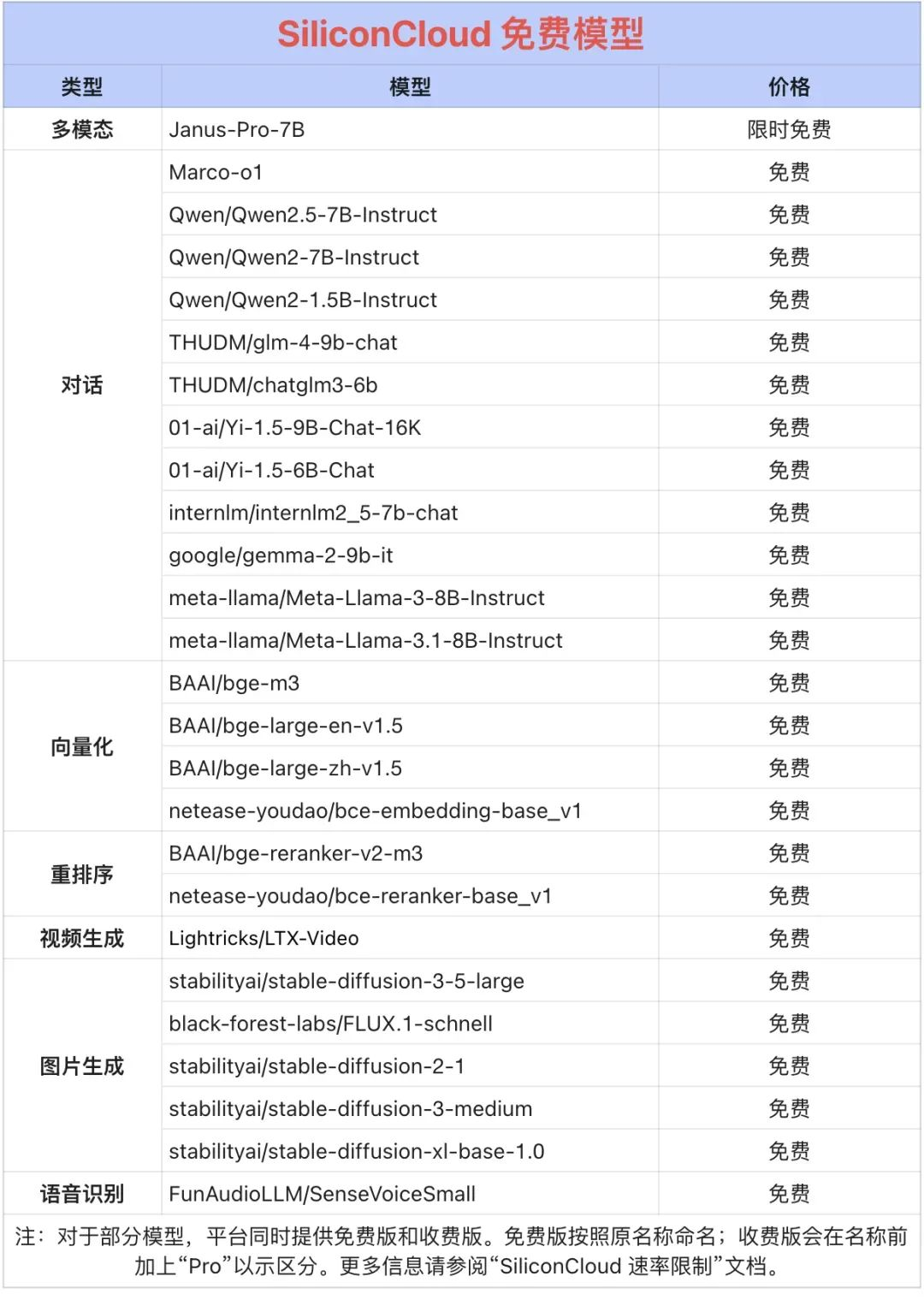
Darunter sind mehr als 20 große Modell-APIs wie Qwen2.5 (7B) und Llama3.1 (8B), die kostenlos genutzt werden können und es Entwicklern und Produktmanagern ermöglichen, "Token-Freiheit" zu erlangen, ohne sich um die Kosten für die Rechenleistung während der Forschungs- und Entwicklungsphase und die groß angelegte Werbung sorgen zu müssen.


