

Letzte Woche kündigte DeepSeek an, nächste Woche fünf Projekte als Open Source freizugeben:

Internetnutzer sagten: „Dieses Mal ist OpenAI wirklich da.“
Gerade erst kam das erste Open-Source-Projekt im Zusammenhang mit der Inferenzbeschleunigung, FlashMLA:
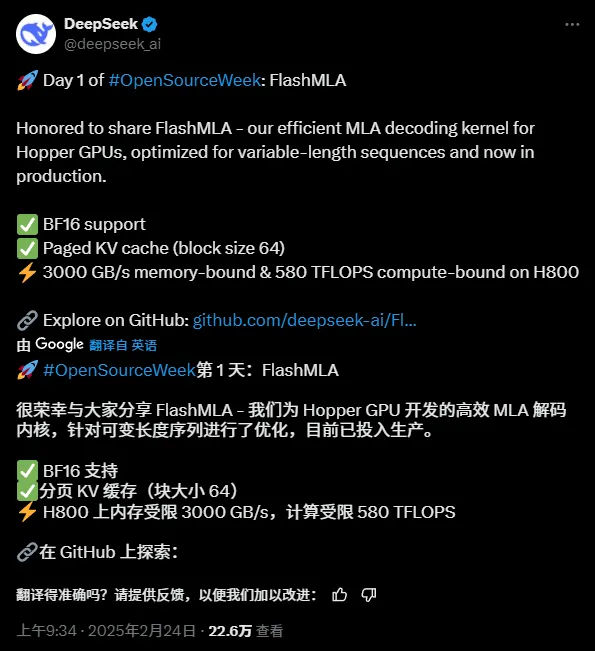
Adresse des Open-Source-Projekts:
Es ist seit zwei Stunden Open Source und Github hat bereits über 2,7.000 Sterne:
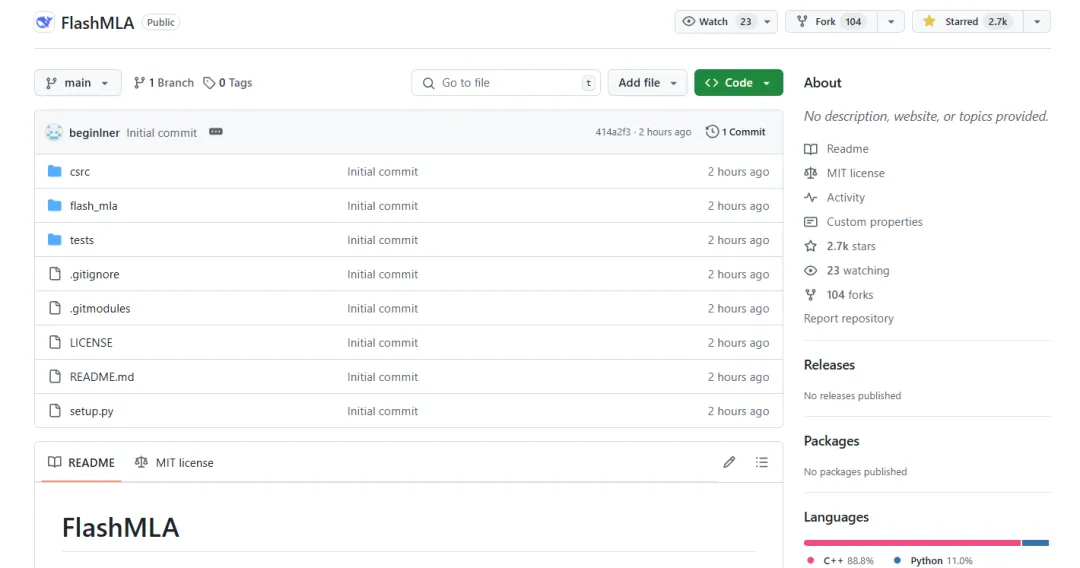
Die Kernfunktion des Projektes ist:
„FlashMLA ist ein effizienter MLA-Dekodierungskernel für Hopper-GPUs, optimiert für die Bereitstellung von Sequenzen variabler Länge.“
Übersetzt heißt das:
„FlashMLA ist ein effizienter MLA-Dekodierungskernel, der für GPUs mit NVIDIA Hopper-Architektur optimiert ist, insbesondere für Service-Szenarien, die Sequenzen mit variabler Länge verarbeiten.“
Kurzgesagt:
FlashMLA ist ein effizienter Dekodierungskern, der von DeepInference für GPUs mit Hopper-Architektur (wie den H800) entwickelt wurde. Durch die Optimierung der Multi-Head-Potential-Attention-Berechnung von Sequenzen variabler Länge erreicht er die ultimative Leistung von 3000 GB/s Speicherbandbreite und 580 TFLOPS Rechenleistung in der Dekodierungsphase, was die Effizienz des Denkens mit langen Kontexten für große Modelle deutlich verbessert.
Einige Internetnutzer sagten:

Einige Leute verwenden es bereits und sagen: „Pure Engineering“:
Dieses Projekt gehört zur Engineering-Optimierung und quetscht die Hardware-Leistung auf die Limit.
Das Projekt ist sofort einsatzbereit.
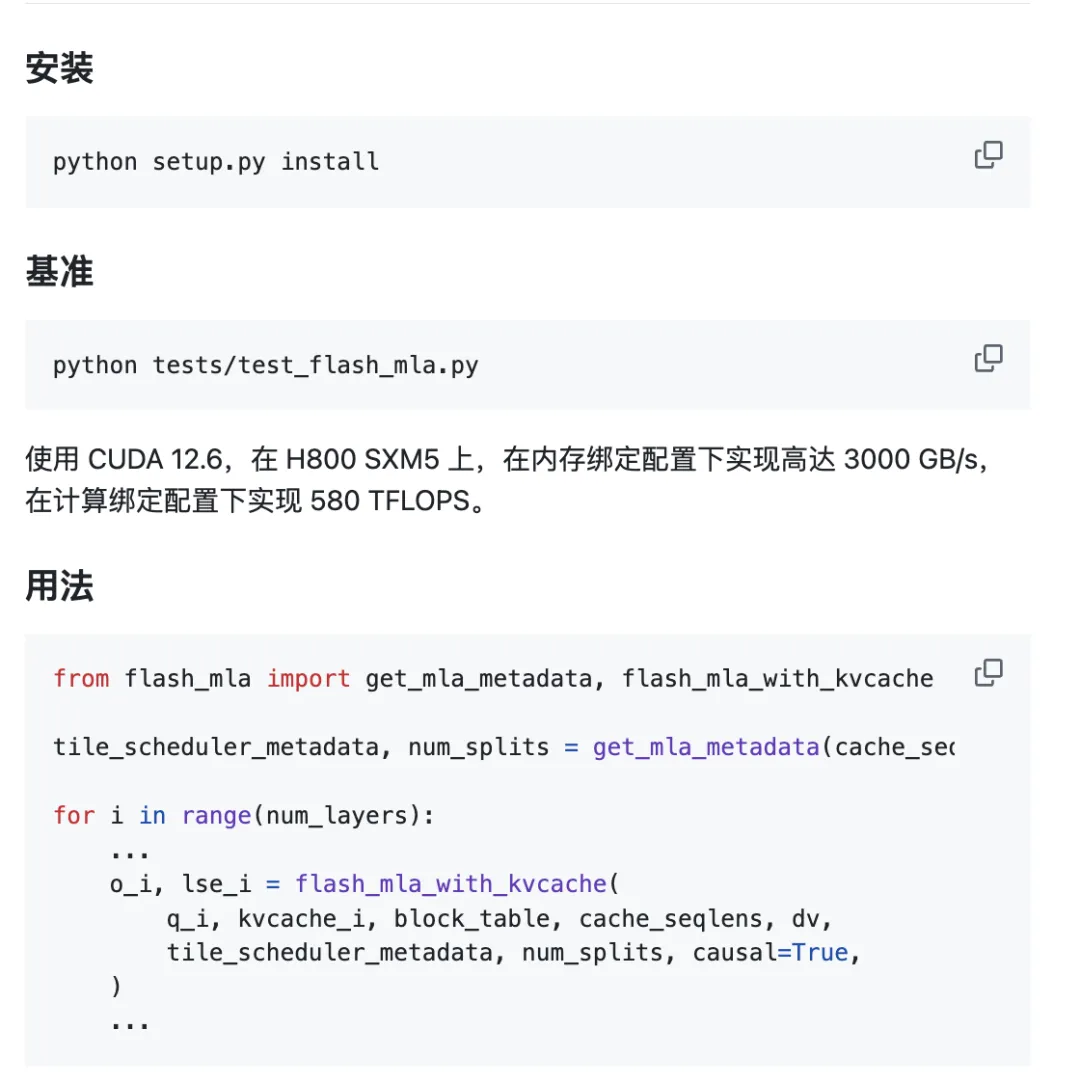
Umgebungsanforderungen:
- Hopper-GPU
- CUDA 12.3 und höher
- PyTorch 2.0 und höher
Am Ende des Projekts erklärte der Beamte außerdem, dass es von den Projekten FlashAttention 2&3 und NVIDIA CUTLASS inspiriert wurde.

FlashAttention kann eine schnelle und speichereffiziente, präzise Aufmerksamkeit erreichen und wird in großen Mainstream-Modellen verwendet. Die neueste Version der dritten Generation kann die Auslastung des H100 auf 75% erhöhen.
Die Trainingsgeschwindigkeit wird um das 1,5- bis 2-fache erhöht und der Rechendurchsatz unter FP16 beträgt bis zu 740 TFLOPs/s, wodurch 75% des theoretisch maximalen Durchsatzes erreicht werden und die Rechenressourcen besser ausgenutzt werden, die zuvor nur 35% betrugen.
FlashMLA erreicht nicht nur einen Leistungssprung durch Optimierung auf Hardwareebene, sondern bietet auch eine sofort einsatzbereite Lösung für technische Praktiken in der KI-Inferenz und stellt damit einen entscheidenden technologischen Durchbruch bei der Beschleunigung der Inferenz großer Modelle dar.
Am ersten Tag gab es eine so große Enthüllung.
Ich freue mich auf die Open-Source-Sachen in den nächsten vier Tagen!
Wie der Internetnutzer sagte:

Der Wal macht Wellen!
DeepSeek ist großartig!



