

DeepSeek-R1 i DeepSeek-V3 wywołały globalną sensację od czasu ich uruchomienia na zasadach open source.
Są one prezentem od zespołu DeepSeek dla całej ludzkości i szczerze cieszymy się z ich sukcesu.
Po wielu dniach ciężkiej pracy zespołów Silicon Mobility i Huawei Cloud, dziś dajemy chińskim użytkownikom prezent z okazji chińskiego Nowego Roku: Platforma usług w chmurze na dużą skalę SiliconCloud wprowadziła na rynek modele DeepSeek-V3 i DeepSeek-R1, które są oparte na usłudze w chmurze Huawei Cloud Ascend.
Należy podkreślić, że otrzymaliśmy ogromne wsparcie od DeepSeek i Huawei Cloud, zarówno przy adaptacji DeepSeek-R1 & V3 na Ascend, jak i w procesie uruchamiania innych modeli wcześniej, i chcielibyśmy wyrazić głęboką wdzięczność i wysoki szacunek.
Cechy
Te dwa modele wprowadzone przez SiliconCloud obejmują głównie pięć głównych funkcji:
W oparciu o usługę chmurową Huawei Cloud Ascend uruchomiliśmy DeepSeek x Silicon Mobility x Usługa wnioskowania modelowego Huawei Cloud R1 i V3 po raz pierwszy.
Dzięki wspólnym innowacjom obu stron i wsparciu samodzielnie opracowanego silnika akceleracji wnioskowania, model DeepSeek wdrożony przez zespół Silicon Mobility w oparciu o usługę chmurową Huawei Cloud Ascend może osiągnąć taki sam efekt, jak wysokiej klasy model wdrażania GPU na świecie.
Zapewnienie stabilnych usług wnioskowania na poziomie produkcyjnym DeepSeek-R1 i V3. Pozwala to programistom na stabilne działanie w środowiskach produkcyjnych na dużą skalę i spełnia potrzeby komercyjnego wdrożenia. Usługi Huawei Cloud Ascend AI zapewniają dużą, elastyczną i wystarczającą moc obliczeniową.
Nie ma progu wdrożenia, co pozwala programistom skupić się bardziej na tworzeniu aplikacji. Podczas tworzenia aplikacji mogą oni bezpośrednio wywoływać interfejs API SiliconCloud, co zapewnia łatwiejsze i bardziej przyjazne dla użytkownika doświadczenie.
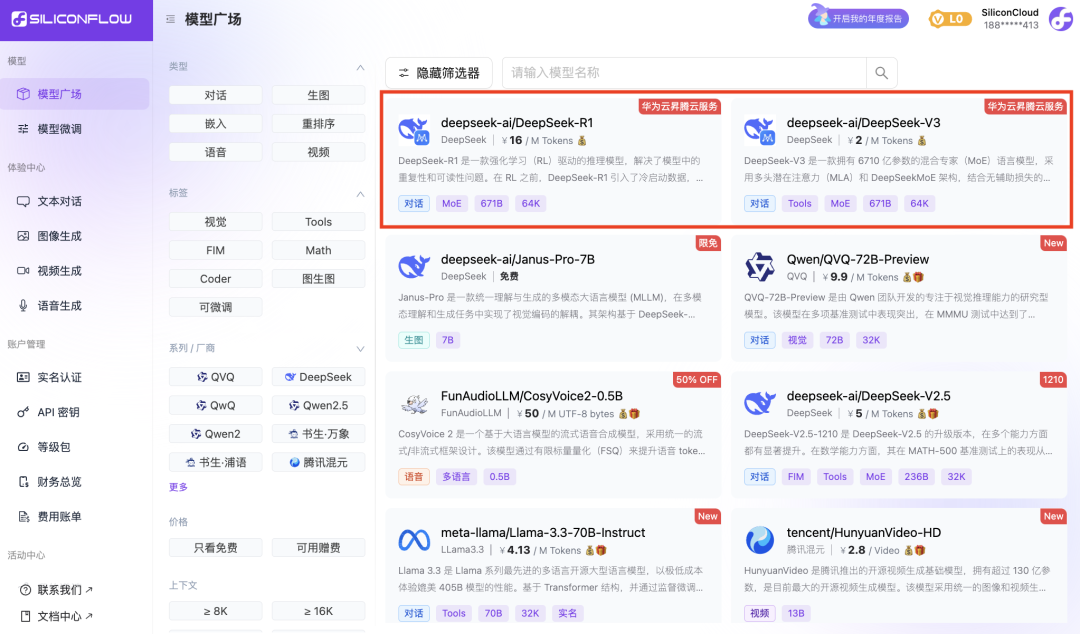
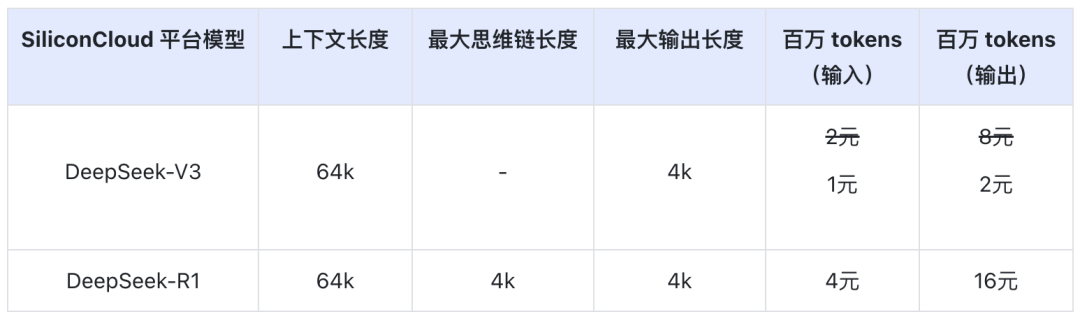
Cena DeepSeek-V3 na SiliconCloud podczas oficjalnego okresu rabatowego (do 24:00 8 lutego) wynosi ¥1 / M tokenów (wejście) i ¥2 / M tokenów (wyjście), a cena DeepSeek-R1 wynosi ¥4 / M tokenów (wejście) i ¥16 / M tokenów (wyjście).
Doświadczenie online
DeepSeek-R1 z SiliconCloud
DeepSeek-V3 z SiliconCloud
Dokumentacja API
Deweloperzy mogą doświadczyć efektu akceleracji DeepSeek-R1 i V3 na krajowych chipach w SiliconCloud. Szybsza prędkość wyjściowa jest nadal stale optymalizowana.


Doświadczenie w aplikacjach klienckich
Jeśli chcesz korzystać z modelu DeepSeek-R1 i V3 bezpośrednio w aplikacji klienckiej, możesz zainstalować lokalnie następujące produkty i uzyskać dostęp do interfejsu API SiliconCloud (możesz dostosować i dodać te dwa modele), aby korzystać z DeepSeek-R1 i V3.
- Duże modelowe aplikacje klienckie: ChatBox, Cherry Studio, OneAPI, LobeChat, NextChat
- Aplikacje do generowania kodu: KursorWindsurf, Cline
- Duża platforma do tworzenia aplikacji:Dify
- Baza wiedzy AI:Obsidian AIorazFastGPT
- Wtyczka do tłumaczenia:Immersive Translate iEurodict
Więcej samouczków dotyczących scenariuszy i dostępu do przypadków użycia można znaleźć na stronie tutaj
Token Factory SiliconCloud
Qwen2.5 (7B) itp. Ponad 20 darmowych modeli
Jako kompleksowa platforma usług w chmurze dla dużych modeli, SiliconCloud dokłada wszelkich starań, aby zapewnić programistom interfejsy API modeli, które są niezwykle responsywne, niedrogie, wszechstronne i zapewniają jedwabiście płynne wrażenia.
Oprócz DeepSeek-R1 i DeepSeek-V3, SiliconCloud wprowadził również Janus-Pro-7B, CosyVoice2, QVQ-72B-Preview, DeepSeek-VL2, DeepSeek-V2.5-1210, Llama-3.3-70B-Instruct, HunyuanVideo, fish-speech-1.5, Qwen2.5 -7B/14B/32B/72B, FLUX.1, InternLM2.5-20B-Chat, BCE, BGE, SenseVoice-Small, GLM-4-9B-Chat,
dziesiątki dużych modeli językowych typu open source, modeli generowania obrazów/wideo, modeli mowy, modeli kodu/matematyki oraz modeli wektorowych i zmieniających kolejność.
Platforma pozwala programistom swobodnie porównywać i łączyć duże modele różnych modalności, aby wybrać najlepszą praktykę dla aplikacji generatywnej sztucznej inteligencji.
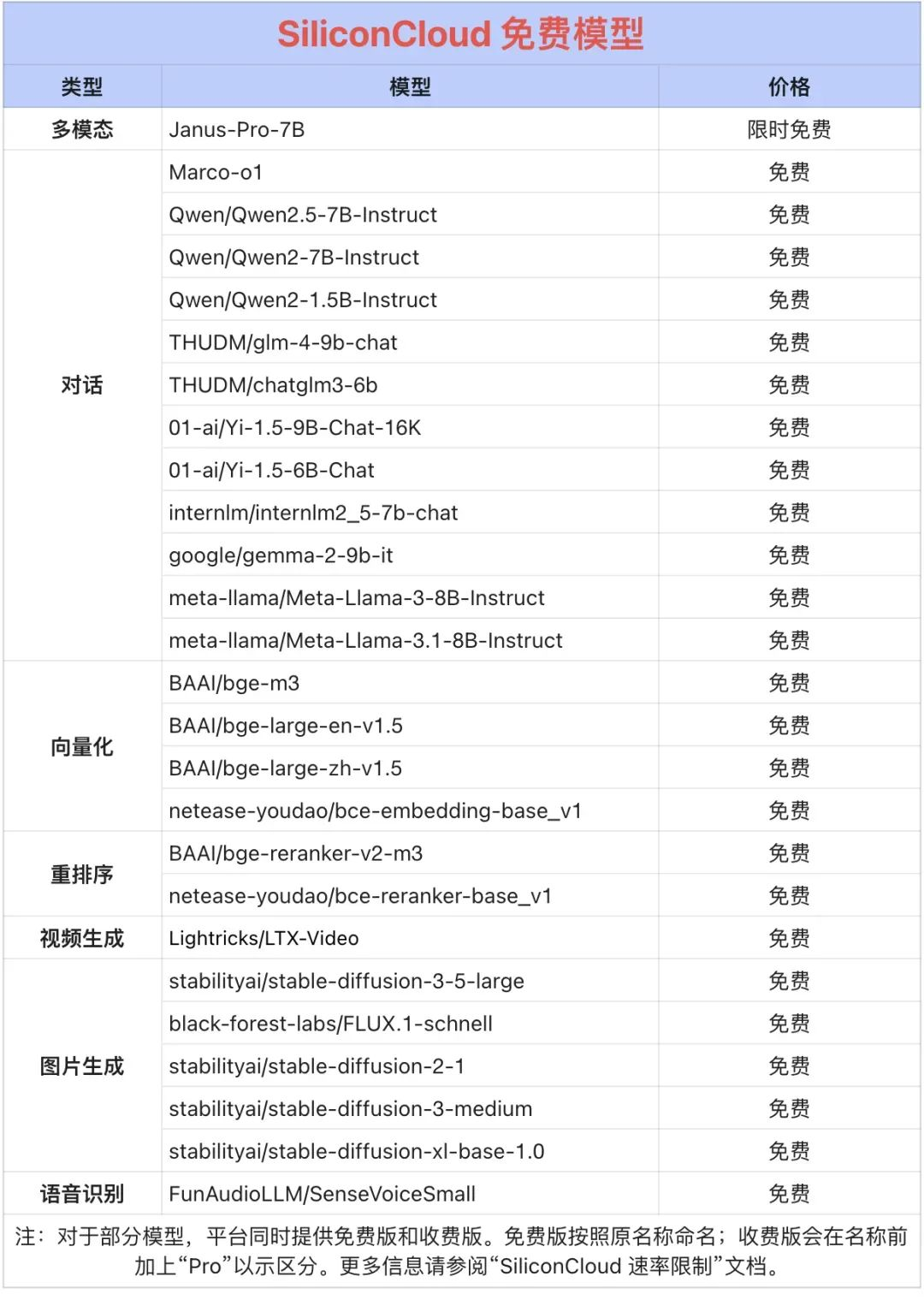
Wśród nich ponad 20 dużych modelowych interfejsów API, takich jak Qwen2.5 (7B) i Llama3.1 (8B), jest darmowych w użyciu, umożliwiając programistom i menedżerom produktów osiągnięcie "tokenowej wolności" bez martwienia się o koszty mocy obliczeniowej na etapie badań i rozwoju oraz promocji na dużą skalę.



