

Berättelsen om Gemini 2.0 accelererar.
Flash Thinking Experimental-versionen i december gav utvecklarna en fungerande modell med låg latens och hög prestanda.
Tidigare i år uppdaterades 2.0 Flash Thinking Experimental i Google AI Studio för att ytterligare förbättra prestandan genom att kombinera hastigheten på Flash med förbättrade slutledningsmöjligheter.
Förra veckan lanserades den uppdaterade versionen 2.0 Flash helt på Geminis stationära och mobila appar.
Idag har tre nya medlemmar avslöjats samtidigt: den experimentella versionen av Gemini 2.0 Pro, som hittills har presterat bäst i kodning och komplexa uppmaningar, den kostnadseffektiva 2.0 Flash-Lite och den tänkande-förbättrade versionen 2.0 Flash Thinking.
Gemini 2.0 Pro rankas först i alla kategorier. Gemini-2.0-Flash rankas bland de tre bästa i kodning, matematik och pussel. Flash-lite rankas bland de tio bästa i alla kategorier.
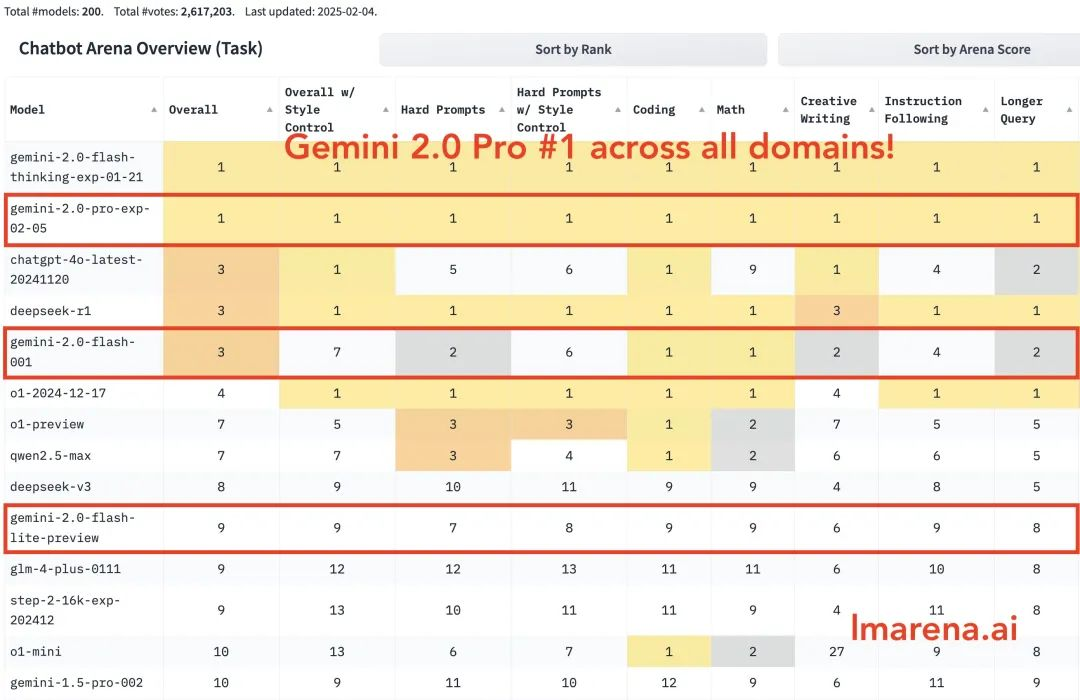

En jämförelsetabell över de tre modellernas förmågor:
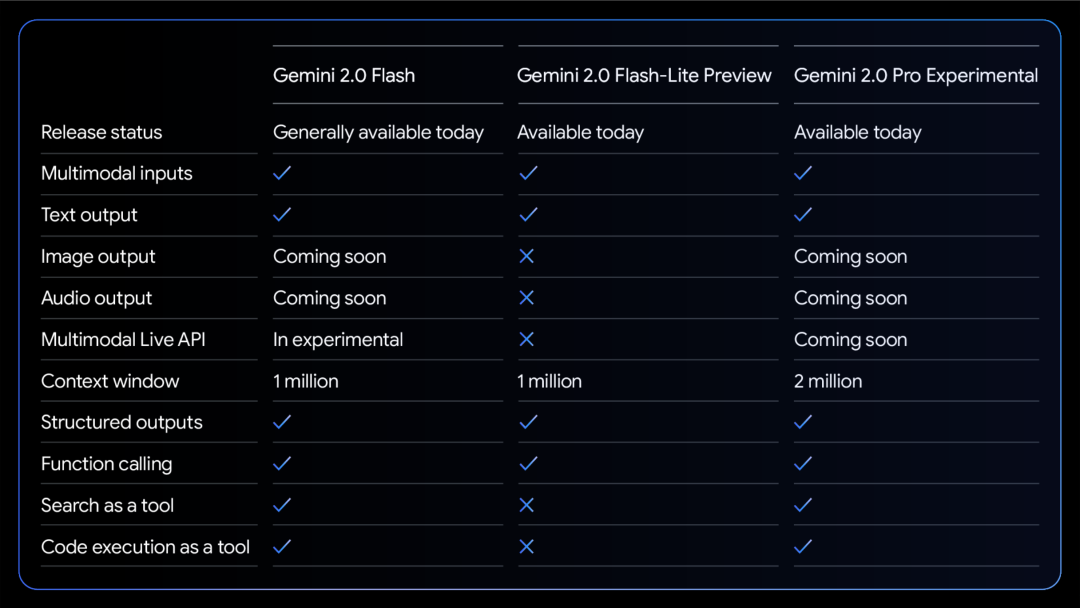
Alla modeller stöder multimodal in- och utmatningstext.
Fler modala förmågor är på väg. Modellstyrkadiagram i kodningsarenan
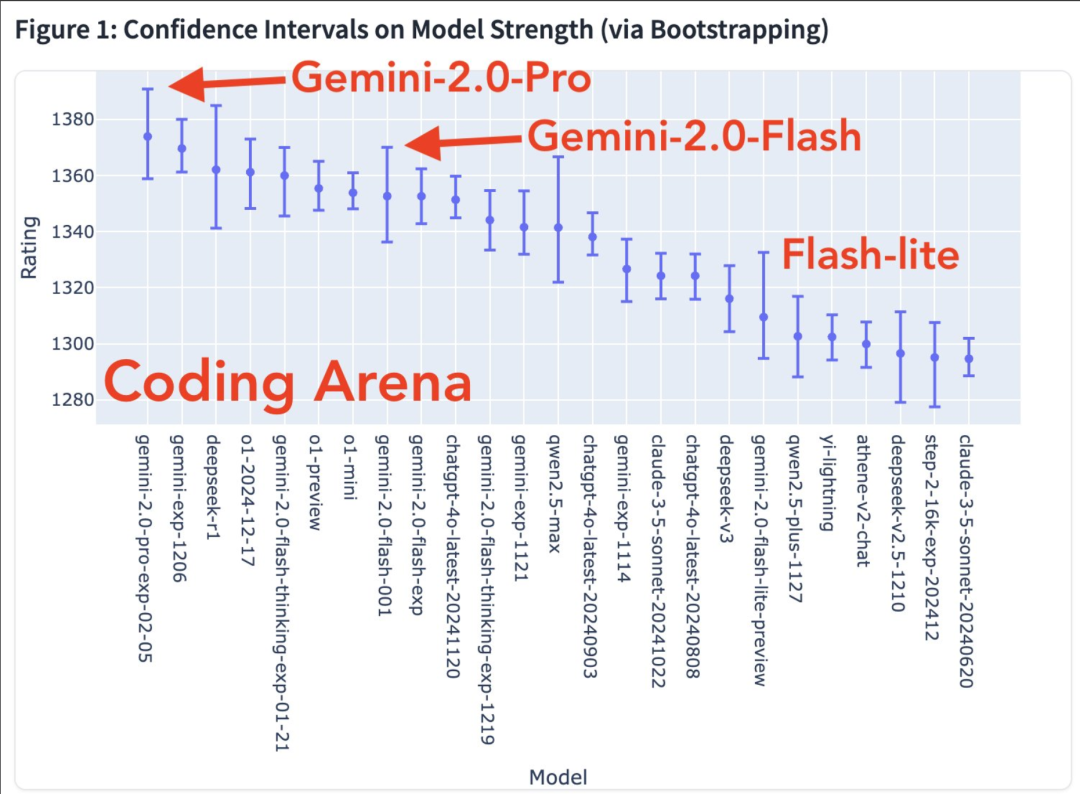
Värmekarta för vinsthastighet

Google behandlar gratisanvändare bättre än OpenAI behandlar Plus-användare. Fri tillgång till Gemini 2.0 Pro Experimental i AI Studio:
Deepseek-tjänsten visar alltid ett fel som väntar... Kom ihåg att den första modellen utan slutledning också var 2.0 Flash Thinking, som användes i Google aistudio.
Dessutom finns det webbversion av Gemini:
Det finns också en ansluten slutledningsmodell (så varför separera den...)

Google släppte den experimentella versionen av Gemini 2.0 Pro, och förbättringen av officiella benchmark-tester är ganska iögonfallande.

Den har de mest kraftfulla kodningsmöjligheterna och förmågan att bearbeta komplexa uppmaningar, och har en bättre förmåga att förstå och resonera om världskunskap än någon modell som släppts av Google hittills.
Den har det största kontextfönstret (200k, och mitt långa sammanhang är en relativt stor fördel med Gemini-modellen), vilket gör det möjligt för den att heltäckande analysera och förstå en stor mängd information, och att anropa verktyg som Google-sökning och kodexekvering.
I MATH-testet uppnådde den 91.8%, en ökning med cirka 5 procentenheter jämfört med version 1.5. GPQA-resonemangsförmågan nådde 64.7%, och SimpleQA-världskunskapstestet nådde till och med 44.3%.
Det mest anmärkningsvärda är programmeringsförmågan. Den uppnådde 36.0% i LiveCodeBench-testet, och Bird-SQL-konverteringsnoggrannheten översteg 59.3%. Tillsammans med det superstora sammanhangsfönstret på 2 miljoner tokens räcker det för att hantera de mest komplexa kodanalysuppgifterna.

Du kan prova det i markören.
Förmågan att förstå flera språk är också imponerande, med ett globalt MMLU-testresultat på 86.5%. Bildförståelse MMMU är 72.7%, och videoanalysförmåga är 71.9%.
Gemini 2.0 Flash-Lite är en intressant balans.
Den bibehåller hastigheten och kostnaden för 1,5 Flash, men ger bättre prestanda. Kontextfönstret med 1 miljon tokens gör att den kan bearbeta mer information.
Det mest praktiska är dess pris/prestanda-förhållande: bildtextgenerering för 40 000 bilder kostar mindre än $1. Detta gör AI mer jordnära.

Bloggaren Shrivastava nämnde: Gemini 2.0 Pro-kodning är galen!
Tips: använd Three.js för att skapa en solsystemsimulering. Lägg till en tidsskala, en rullgardinsmeny för fokus, visa banor och visa etiketter. Skapa allt i en fil så att jag kan klistra in det i en onlineredigerare och se resultatet.

Dessutom nämnde vissa användare att Gemini 2.0 Flash gav bättre resultat i ett av hans egna paradoxtester:

Slutligen nämnde Google att säkerheten i Gemini 2.0, inte bara patchen, är kärnan i designen från början.
Låt modellen lära sig att vara självkritisk. Använd förstärkningsinlärning för att låta Gemini utvärdera sina egna svar och ge mer korrekt feedback. Detta gör den mer robust när man hanterar känsliga ämnen.
Den automatiska testningen av röda team är intressant. Den är speciellt utformad för att förhindra injicering av indirekta promptord, vilket är som att utrusta AI:n med ett immunsystem för att förhindra att någon döljer skadliga kommandon i data.




