

Het verhaal van Tweelingennik 2.0 versnelt.
De experimentele versie van Flash Thinking in december bood ontwikkelaars een werkend model met lage latentie en hoge prestaties.
Eerder dit jaar werd Flash Thinking Experimental 2.0 geüpdatet in Google AI Studio om de prestaties verder te verbeteren door de snelheid van Flash te combineren met verbeterde inferentiemogelijkheden.
Afgelopen week werd de bijgewerkte versie 2.0 Flash volledig gelanceerd op de Gemini desktop- en mobiele apps.
Vandaag zijn er tegelijkertijd drie nieuwe leden onthuld: de experimentele versie van Gemini 2.0 Pro, die tot nu toe het beste presteerde op het gebied van codering en complexe prompts, de kosteneffectieve 2.0 Flash-Lite en de denkverbeterde versie 2.0 Flash Thinking.
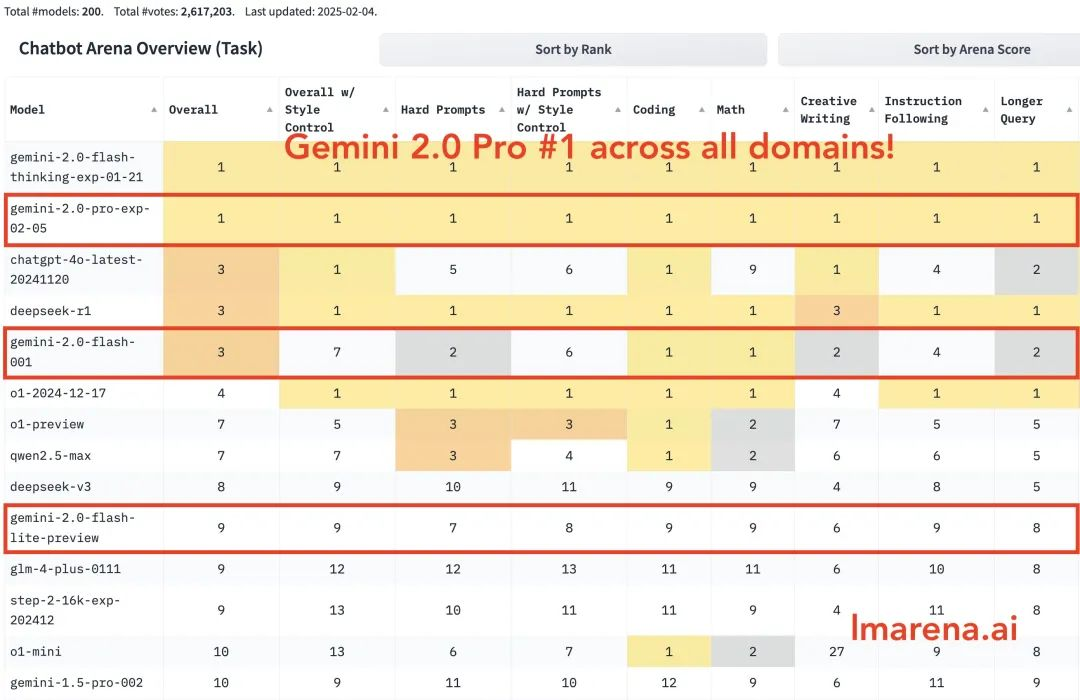
Gemini 2.0 Pro staat op de eerste plaats in alle categorieën. Gemini-2.0-Flash staat in de top drie in codering, wiskunde en puzzels. Flash-lite staat in de top tien in alle categorieën.

Een vergelijkingstabel van de mogelijkheden van de drie modellen:
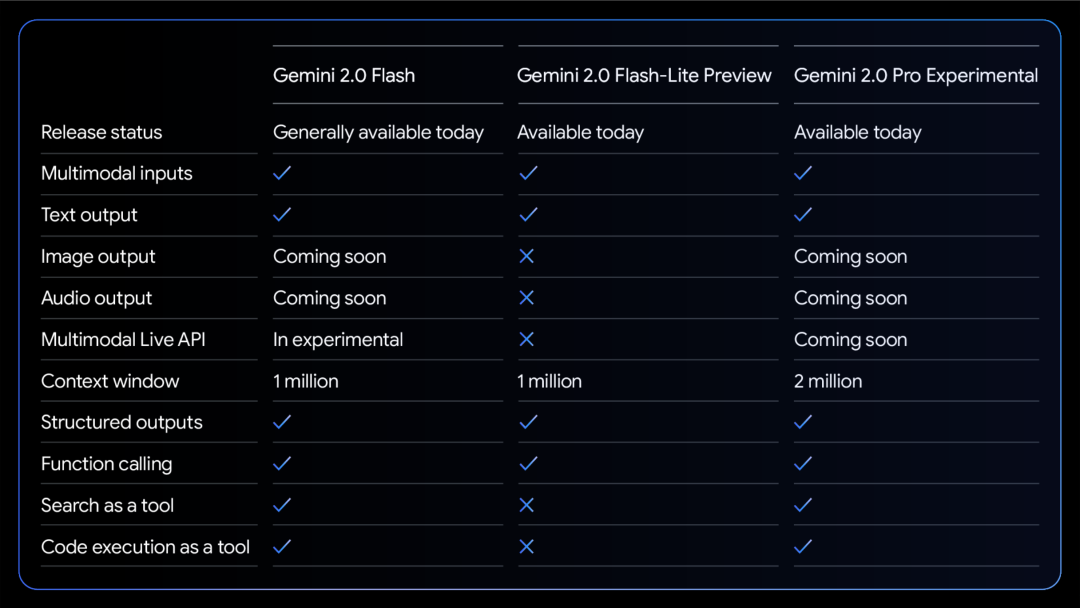
Alle modellen ondersteunen multimodale invoer- en uitvoertekst.
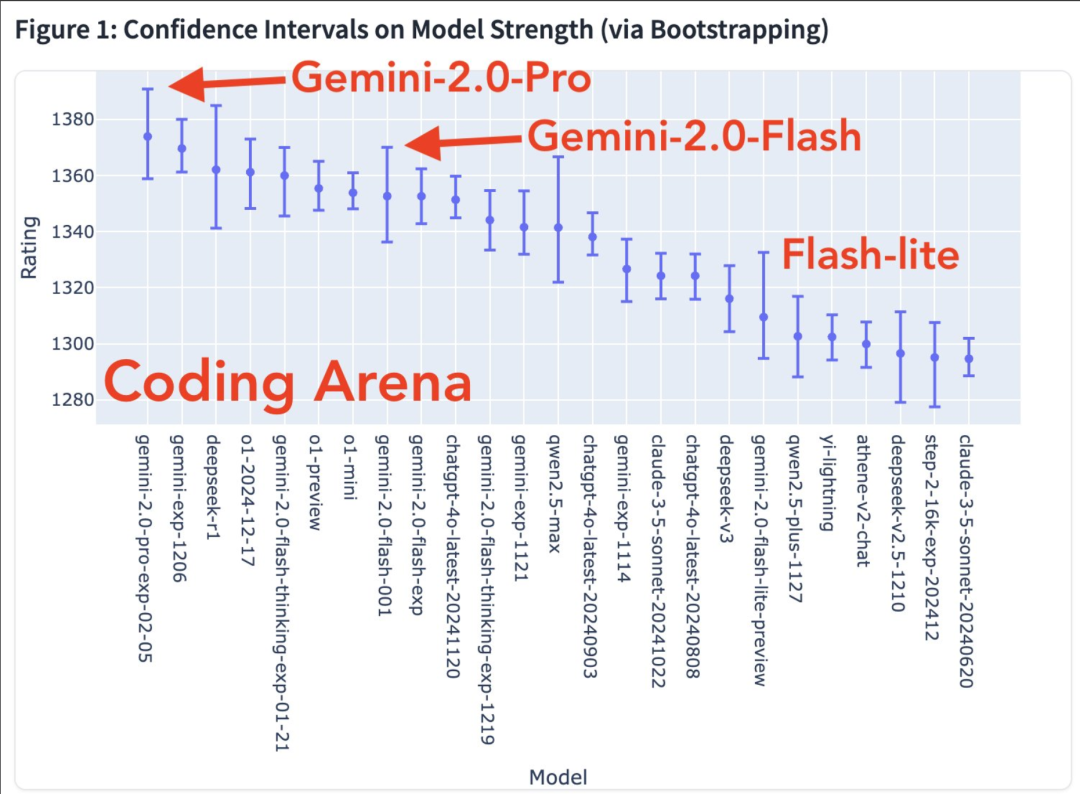
Er komen meer modale mogelijkheden. Model strength chart in de coding arena
Heatmap voor winstpercentage

Google behandelt gratis gebruikers beter dan OpenAI Plus-gebruikers behandelt. Gratis toegang tot Gemini 2.0 Pro Experimental in AI Studio:
De Deepseek-service geeft altijd een foutmelding weer bij het wachten… Vergeet niet dat het eerste inferentievrije model ook Flash Thinking 2.0 was, dat werd gebruikt in Google aistudio.
Daarnaast is er de webversie van Gemini:
Er is ook een samenhangend inferentiemodel (waarom zouden we het dan scheiden…)

Google heeft de experimentele versie van Gemini 2.0 Pro uitgebracht en de verbeteringen in officiële benchmarktests zijn opvallend.

Het beschikt over de krachtigste coderingsmogelijkheden, kan complexe opdrachten verwerken en kan wereldkennis beter begrijpen en erover redeneren dan elk ander model dat Google tot nu toe heeft uitgebracht.
Het heeft het grootste contextvenster (200k, en mijn lange context is een relatief groot voordeel van het Gemini-model), waardoor het een grote hoeveelheid informatie uitgebreid kan analyseren en begrijpen, en hulpmiddelen zoals Google-zoekopdrachten en code-uitvoering kan aanroepen.
In de MATH-test behaalde het een score van 91,8%, een stijging van ongeveer 5 procentpunten ten opzichte van versie 1.5. Het GPQA-redeneervermogen bereikte een score van 64,7% en de SimpleQA-wereldkennistest zelfs een score van 44,3%.
Het meest opvallende is het programmeervermogen. Het behaalde 36.0% in de LiveCodeBench-test en de Bird-SQL-conversienauwkeurigheid overtrof 59.3%. Gecombineerd met het supergrote contextvenster van 2 miljoen tokens is het voldoende om de meest complexe codeanalysetaken uit te voeren.

Je kunt het in de cursor uitproberen.
Ook het vermogen om meerdere talen te begrijpen is indrukwekkend, met een Global MMLU-testscore van 86,5%. Het vermogen om afbeeldingen te begrijpen (MMMU) is 72,7% en het vermogen om video's te analyseren is 71,9%.
Gemini 2.0 Flash-Lite is een interessante balans.
Het behoudt de snelheid en kosten van 1.5 Flash, maar levert betere prestaties. Het contextvenster met 1 miljoen tokens zorgt ervoor dat het meer informatie kan verwerken.
Het meest praktische is de prijs/prestatieverhouding: het genereren van onderschriften voor 40.000 foto's kost minder dan $1. Dit maakt AI nuchterder.

Blogger Shrivastava zei: Gemini 2.0 Pro-codering is waanzinnig!
Tip: gebruik Three.js om een simulatie van het zonnestelsel te maken. Voeg een tijdschaal, een focus dropdown menu, toon banen en toon labels. Maak alles in één bestand zodat ik het in een online editor kan plakken en de output kan bekijken.

Bovendien gaven sommige gebruikers aan dat Gemini 2.0 Flash betere resultaten opleverde in een van zijn eigen paradoxtests:

Tot slot gaf Google aan dat de beveiliging van Gemini 2.0, en niet alleen de patch, vanaf het begin centraal staat in het ontwerp.
Laat het model leren zelfkritisch te zijn. Gebruik reinforcement learning om Gemini zijn eigen antwoorden te laten evalueren en nauwkeurigere feedback te geven. Dit maakt het robuuster bij het omgaan met gevoelige onderwerpen.
De geautomatiseerde red team-test is interessant. Het is specifiek ontworpen om de injectie van indirecte promptwoorden te voorkomen, wat vergelijkbaar is met het uitrusten van de AI met een immuunsysteem om te voorkomen dat iemand kwaadaardige commando's in de data verbergt.



