

Verlede week het DeepSeek aangekondig dat dit volgende week vyf projekte sal oopmaak:

Netizens het gesê: "Hierdie keer is OpenAI regtig hier."
Netnou het die eerste oopbronprojek gekom, wat verband hou met afleidingversnelling, FlashMLA:
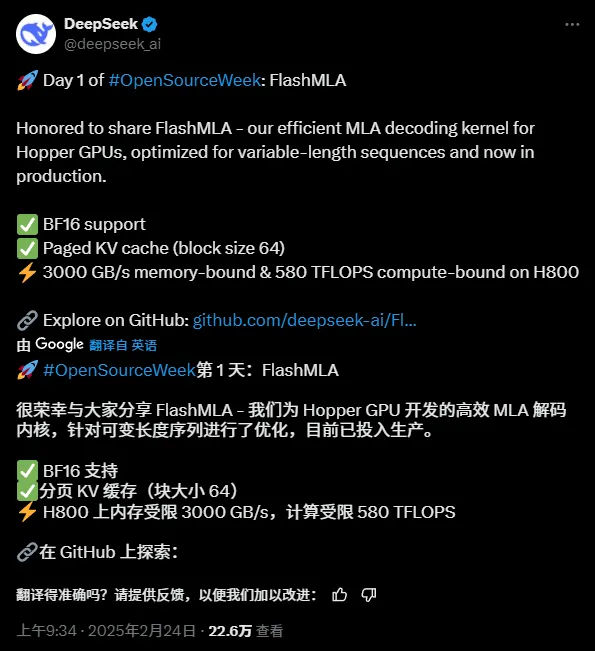
Oopbronprojekadres:
Dit is al twee uur oopbron, en Github het reeds 2.7k+ sterre:
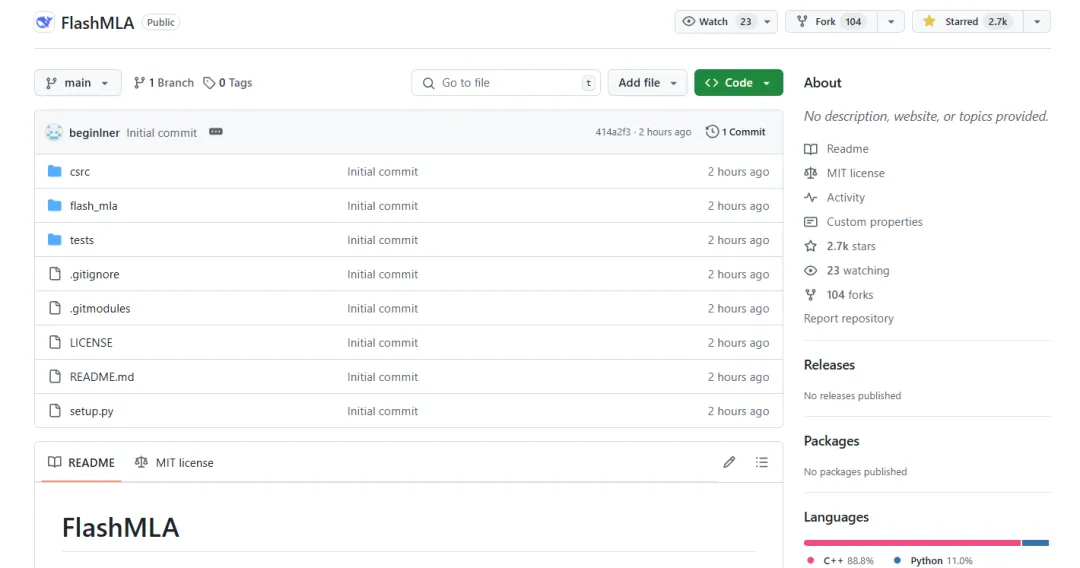
Die kernfunksie van die projek is:
"FlashMLA is 'n doeltreffende MLA-dekoderingkern vir Hopper GPU's, geoptimaliseer vir reekse met veranderlike lengtes wat bedien word."
Vertaal, dit is:
"FlashMLA is 'n doeltreffende MLA-dekoderingskern wat geoptimaliseer is vir NVIDIA Hopper-argitektuur GPU's, spesifiek geoptimaliseer vir diensscenario's wat reekse van veranderlike lengte verwerk."
In 'n neutedop:
FlashMLA is 'n doeltreffende dekoderingskern wat deur DeepInference ontwerp is vir Hopper-argitektuur GPU's (soos die H800). Deur die multi-kop potensiële aandag berekening van veranderlike-lengte rye te optimaliseer, behaal dit die uiteindelike werkverrigting van 3000GB/s geheue bandwydte en 580TFLOPS rekenaarkrag in die dekodering stadium, wat die doeltreffendheid van redenering met lang kontekste vir groot modelle aansienlik verbeter.
Sommige netizens het gesê:

Sommige mense gebruik dit reeds, en hulle sê Pure engineering:
Hierdie projek behoort aan ingenieursoptimalisering en druk die hardeware werkverrigting na die beperk.
Die projek is gereed om uit die boks te gebruik.
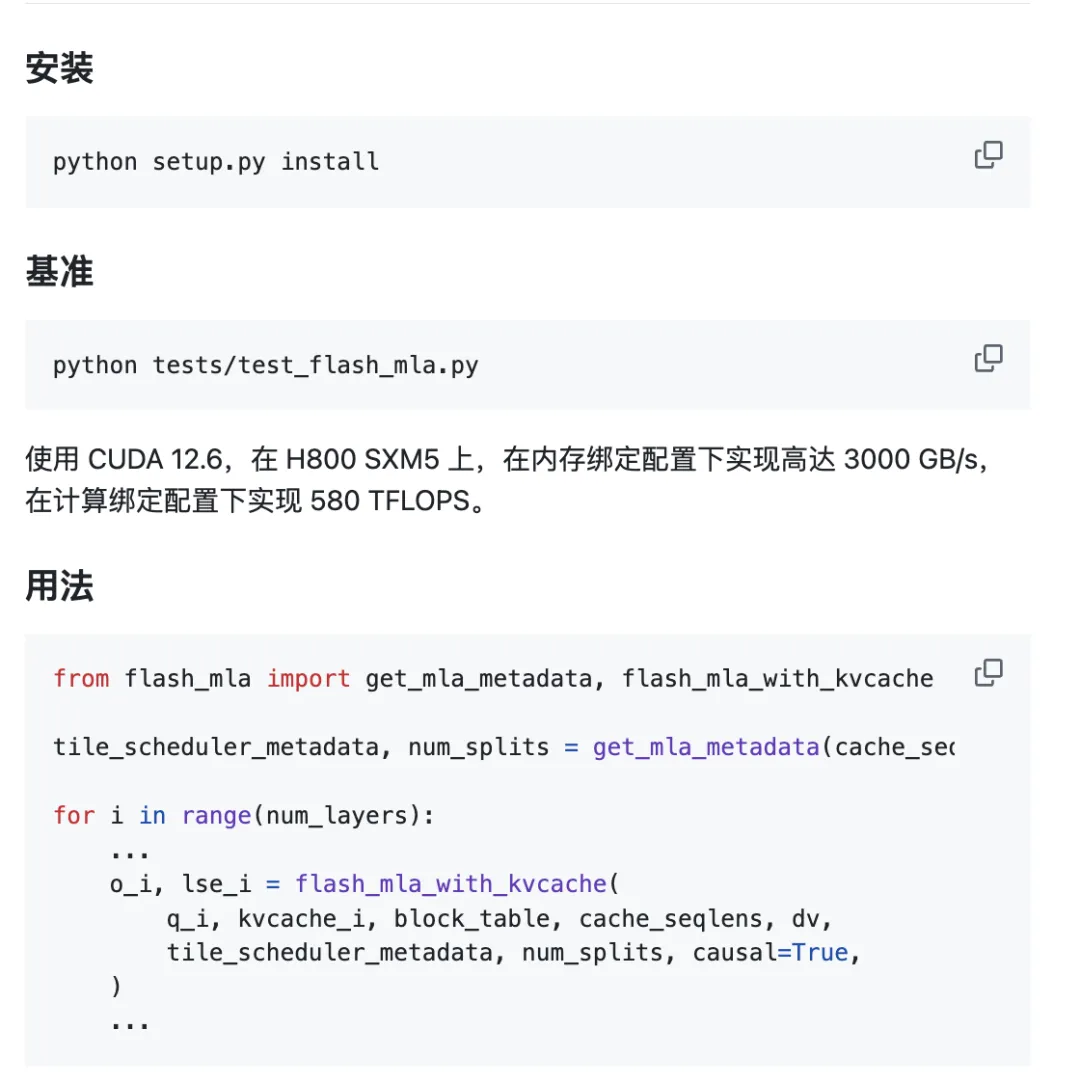
Omgewingsvereistes:
- Hopper GPU
- CUDA 12.3 en hoër
- PyTorch 2.0 en hoër
Aan die einde van die projek het die amptenaar ook gesê dat dit geïnspireer is deur die FlashAttention 2&3- en NVIDIA CUTLASS-projekte.

FlashAttention is in staat om vinnige en geheuedoeltreffende presiese aandag te verkry, en word in hoofstroom groot modelle gebruik. Die jongste derdegenerasie-weergawe kan die gebruikskoers van die H100 tot 75% verhoog.
Opleidingspoed word met 1,5-2 keer verhoog, en die berekeningsdeurset onder FP16 is so hoog as 740 TFLOP's/s, wat 75% van die teoretiese maksimum deurset bereik en meer volle gebruik maak van rekenaarhulpbronne, wat voorheen slegs 35% was.
FlashMLA bereik nie net 'n sprong in werkverrigting deur hardeware-vlakoptimering nie, maar bied ook 'n out-of-the-box oplossing vir ingenieurspraktyke in KI-afleiding, wat 'n belangrike tegnologiese deurbraak word in die versnelling van afleiding van groot modelle.
Daar was so 'n groot onthulling op die eerste dag.
Ek sien uit na die oopbron-dinge in die volgende vier dae!
Soos die netizen gesê het:

Die walvis maak golwe!
DeepSeek is wonderlik!

