

На прошлой неделе DeepSeek объявила, что на следующей неделе откроет исходный код пяти проектов:

Пользователи сети отметили: «На этот раз OpenAI действительно здесь».
Только что появился первый проект с открытым исходным кодом, связанный с ускорением вывода, FlashMLA:
Адрес проекта с открытым исходным кодом:
Его исходный код открыт уже два часа, а на Github уже более 2,7 тыс. звезд:
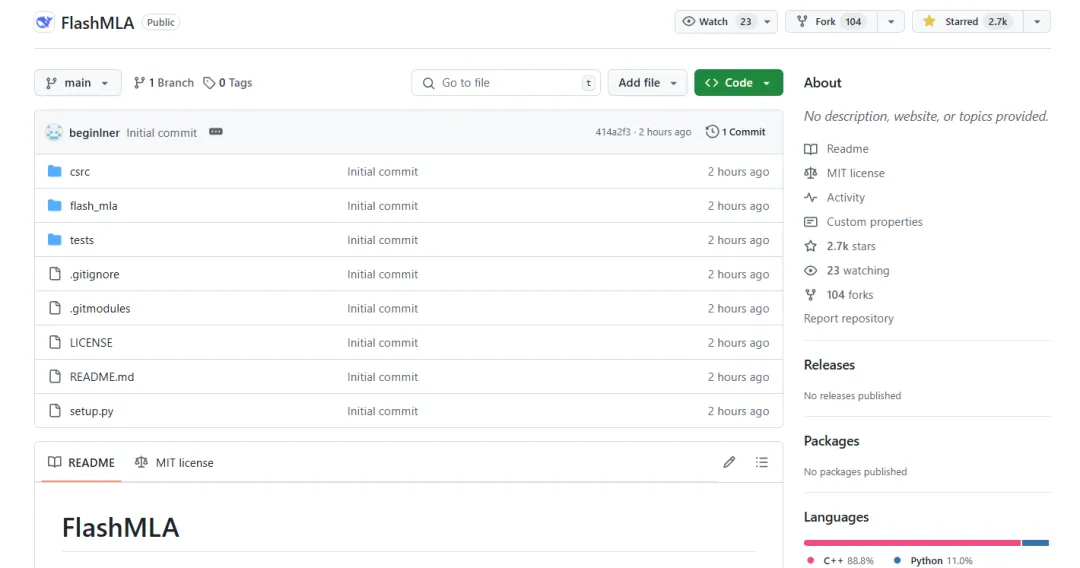
Основная функция проекта:
«FlashMLA — это эффективное ядро декодирования MLA для графических процессоров Hopper, оптимизированное для обслуживания последовательностей переменной длины».
В переводе это:
«FlashMLA — это эффективное ядро декодирования MLA, оптимизированное для графических процессоров с архитектурой NVIDIA Hopper, специально оптимизированное для сценариев обслуживания, обрабатывающих последовательности переменной длины».
Вкратце:
FlashMLA — это эффективное ядро декодирования, разработанное DeepInference для графических процессоров с архитектурой Hopper (например, H800). Оптимизируя многоголовочный расчет потенциального внимания последовательностей переменной длины, он достигает максимальной производительности в 3000 ГБ/с пропускной способности памяти и 580 TFLOPS вычислительной мощности на этапе декодирования, значительно повышая эффективность рассуждений с длинными контекстами для больших моделей.
Некоторые пользователи сети сказали:

Некоторые люди уже используют его и говорят: «Чистая инженерия»:
Этот проект относится к инженерной оптимизации и сжимает производительность оборудования до предел.
Проект готов к использованию сразу после установки.
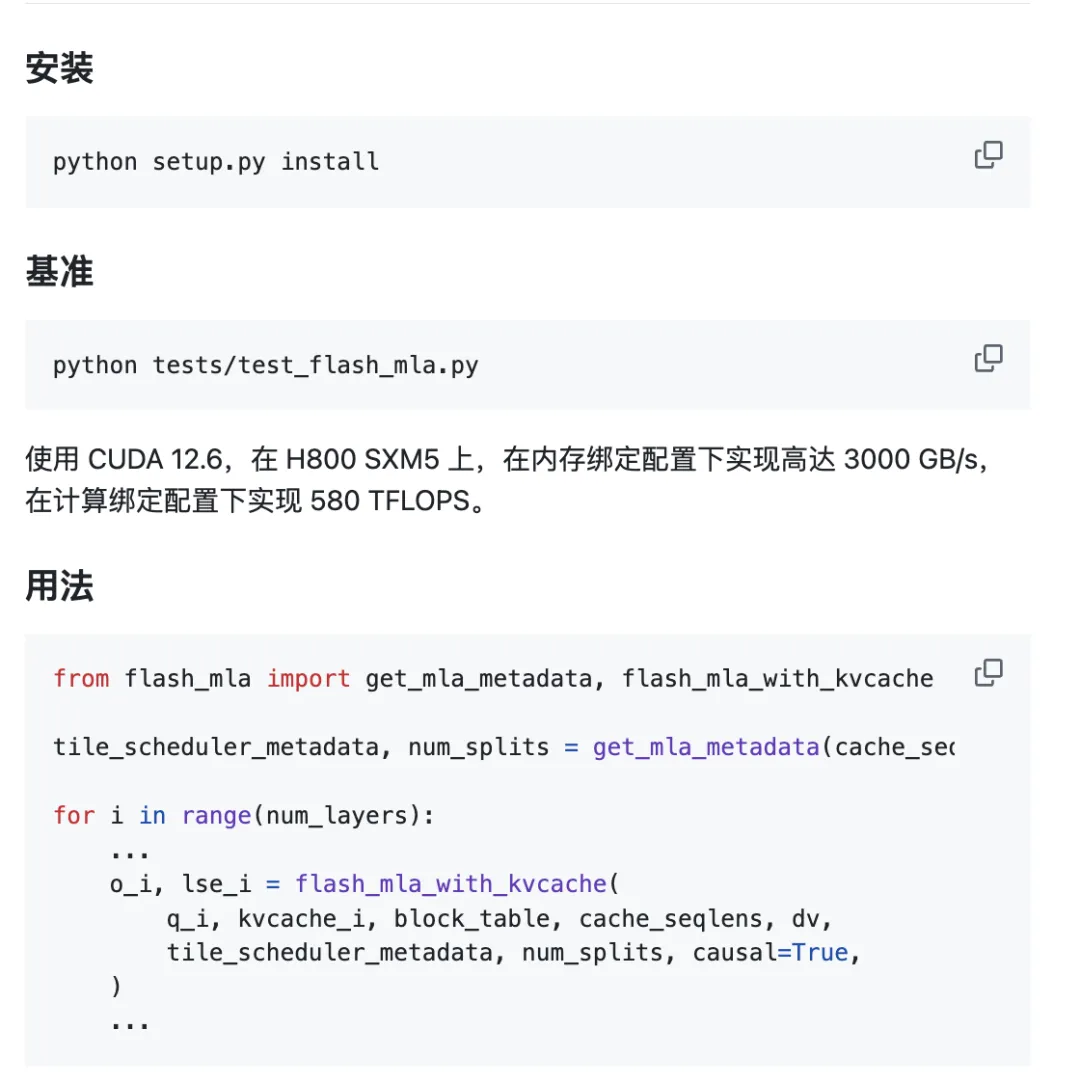
Требования к окружающей среде:
- Графический процессор Hopper
- CUDA 12.3 и выше
- PyTorch 2.0 и выше
В конце проекта официальный представитель также заявил, что он был вдохновлен проектами FlashAttention 2&3 и NVIDIA CUTLASS.

FlashAttention способен достигать быстрого и эффективного по памяти точного внимания и используется в основных больших моделях. Последняя версия третьего поколения может увеличить коэффициент использования H100 до 75%.
Скорость обучения увеличивается в 1,5-2 раза, а производительность вычислений в рамках FP16 достигает 740 TFLOPs/s, достигая 75% от теоретической максимальной производительности и позволяя полнее использовать вычислительные ресурсы, которые ранее составляли всего 35%.
FlashMLA не только достигает скачка производительности за счет оптимизации на уровне аппаратного обеспечения, но и предоставляет готовое решение для инженерных практик в области вывода ИИ, становясь ключевым технологическим прорывом в ускорении вывода больших моделей.
В первый день произошло такое грандиозное открытие.
С нетерпением жду новостей об открытом исходном коде в ближайшие четыре дня!
Как сказал пользователь сети:

Кит поднимает волны!
DeepSeek потрясающий!

