

Миналата седмица DeepSeek обяви, че следващата седмица ще отвори пет проекта с отворен код:

Нетизените казаха: „Този път OpenAI наистина е тук.“
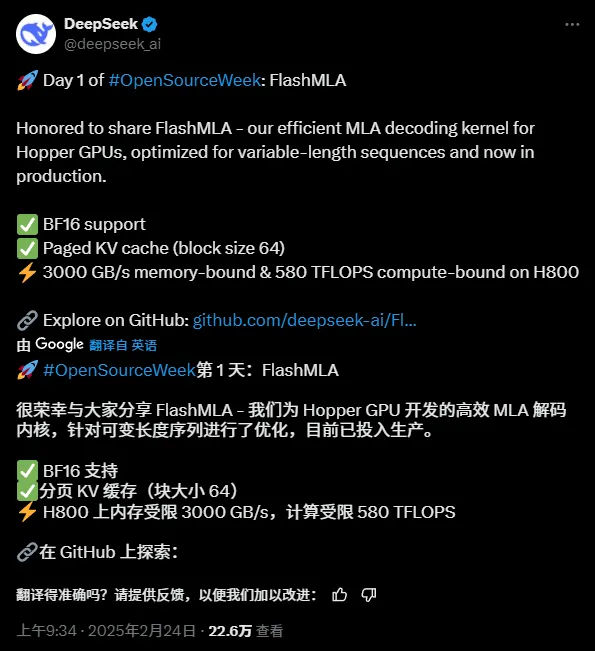
Току-що дойде първият проект с отворен код, свързан с ускоряване на извода, FlashMLA:
Адрес на проекта с отворен код:
Той е с отворен код от два часа, а Github вече има 2,7k+ звезди:
Основната функция на проекта е:
„FlashMLA е ефективно MLA декодиращо ядро за Hopper GPU, оптимизирано за обслужване на последователности с променлива дължина.“
Преведено, така е:
„FlashMLA е ефективно MLA декодиращо ядро, оптимизирано за графични процесори с архитектура NVIDIA Hopper, специално оптимизирано за сервизни сценарии, които обработват последователности с променлива дължина.“
Накратко:
FlashMLA е ефективно декодиращо ядро, проектирано от DeepInference за GPU с Hopper архитектура (като H800). Чрез оптимизиране на изчислението на потенциалното внимание на няколко глави на последователности с променлива дължина, той постига максимална производителност от 3000GB/s честотна лента на паметта и 580TFLOPS изчислителна мощност в етапа на декодиране, като значително подобрява ефективността на разсъжденията с дълги контексти за големи модели.
Някои нетизени казаха:

Някои хора вече го използват и казват Чисто инженерство:
Този проект принадлежи към инженерната оптимизация и намалява производителността на хардуера до лимит.
Проектът е готов за използване от кутията.
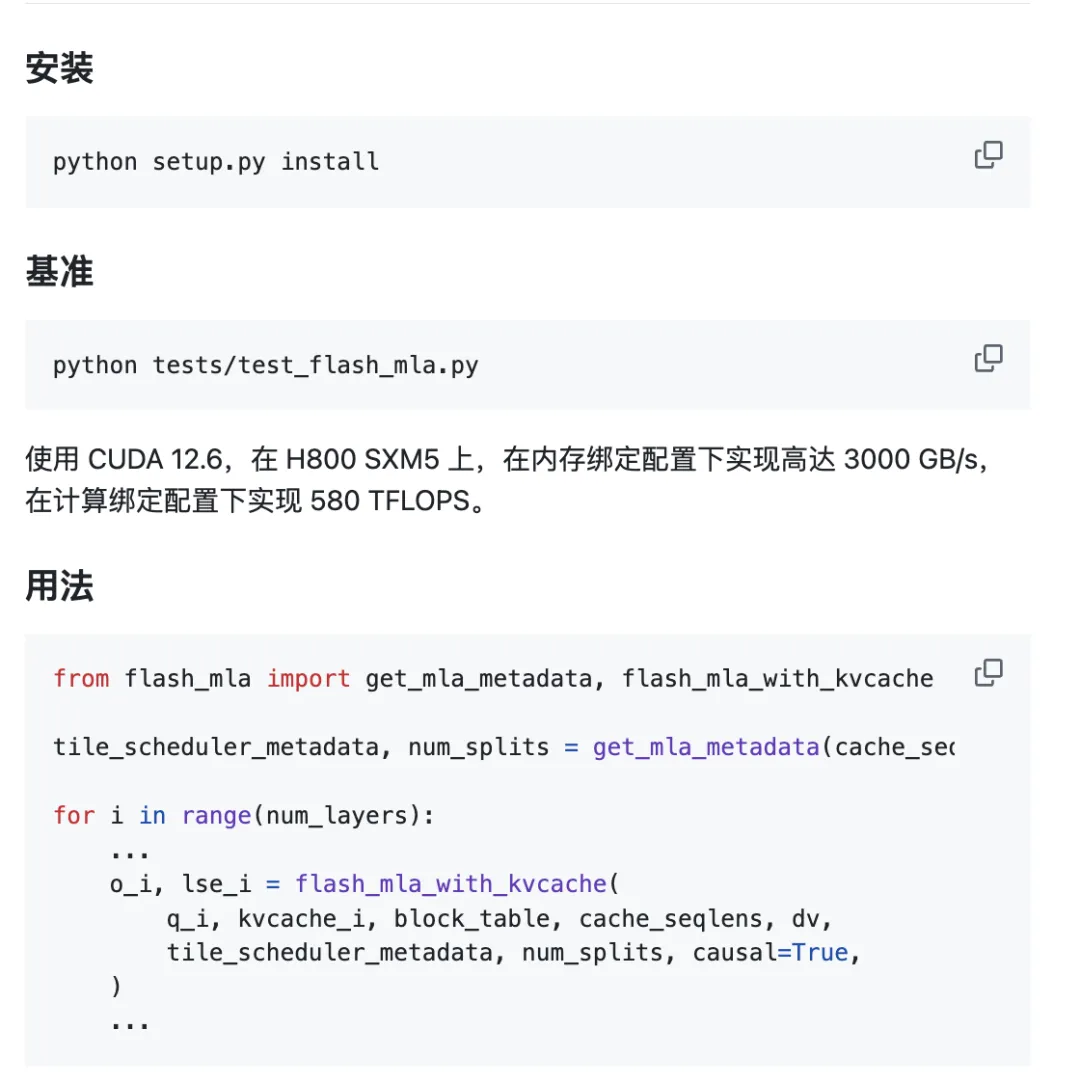
Изисквания за околната среда:
- Хопър GPU
- CUDA 12.3 и по-нова версия
- PyTorch 2.0 и по-нова версия
В края на проекта официалният представител също така заяви, че е вдъхновен от проектите FlashAttention 2&3 и NVIDIA CUTLASS.

FlashAttention е в състояние да постигне бързо и ефективно за паметта прецизно внимание и се използва в основните големи модели. Последната версия от трето поколение може да увеличи степента на използване на H100 до 75%.
Скоростта на обучение се увеличава с 1,5-2 пъти, а изчислителната производителност при FP16 достига 740 TFLOPs/s, достигайки 75% от теоретичната максимална пропускателна способност и по-пълноценно използване на изчислителните ресурси, което преди беше само 35%.
FlashMLA не само постига скок в производителността чрез оптимизация на хардуерно ниво, но също така предоставя готово решение за инженерни практики в изводите на AI, превръщайки се в ключов технологичен пробив в ускоряването на изводите на големи модели.
Имаше толкова голямо разкритие в първия ден.
Очаквам с нетърпение нещата с отворен код през следващите четири дни!
Както каза потребителят на мрежата:

Китът прави вълни!
DeepSeek е страхотен!


