

上週,DeepSeek宣布將於下週開源五個項目:

網友們表示,“這次OpenAI真的來了。”
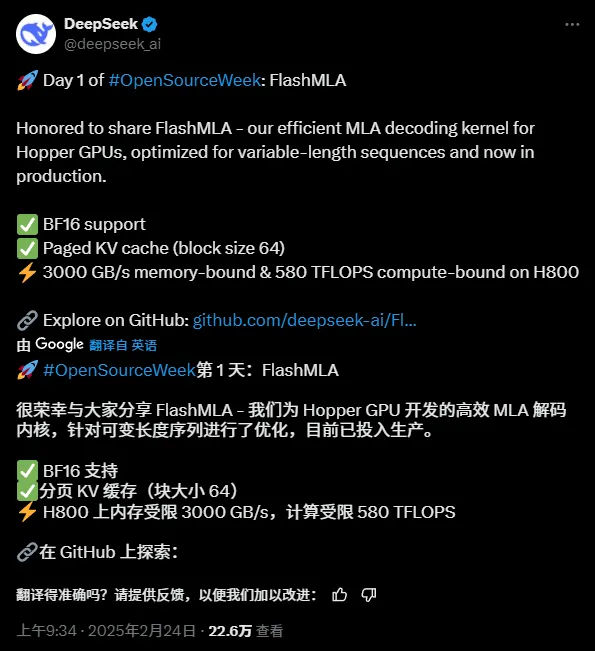
剛剛,第一個開源專案來了,與推理加速相關的,FlashMLA:
開源專案位址:
開源兩小時,Github 已經有 2.7k+ star:
專案的核心功能是:
“FlashMLA 是適用於 Hopper GPU 的高效 MLA 解碼內核,針對可變長度序列服務進行了最佳化。”
翻譯過來就是:
“FlashMLA 是針對 NVIDIA Hopper 架構 GPU 優化的高效 MLA 解碼內核,專門針對處理變長序列的服務場景進行了優化。”
簡而言之:
FlashMLA 是 DeepInference 為 Hopper 架構 GPU(如 H800)設計的高效解碼核心。透過優化變長序列的多頭潛在註意力計算,在解碼階段達到了3000GB/s記憶體頻寬和580TFLOPS算力的極致性能,顯著提升大模型長上下文推理的效率。
有網友表示:

有些人已經在使用它了,他們說純工程:
本專案屬於工程優化與 將硬體效能壓縮到 限制。
該項目已準備好投入使用。
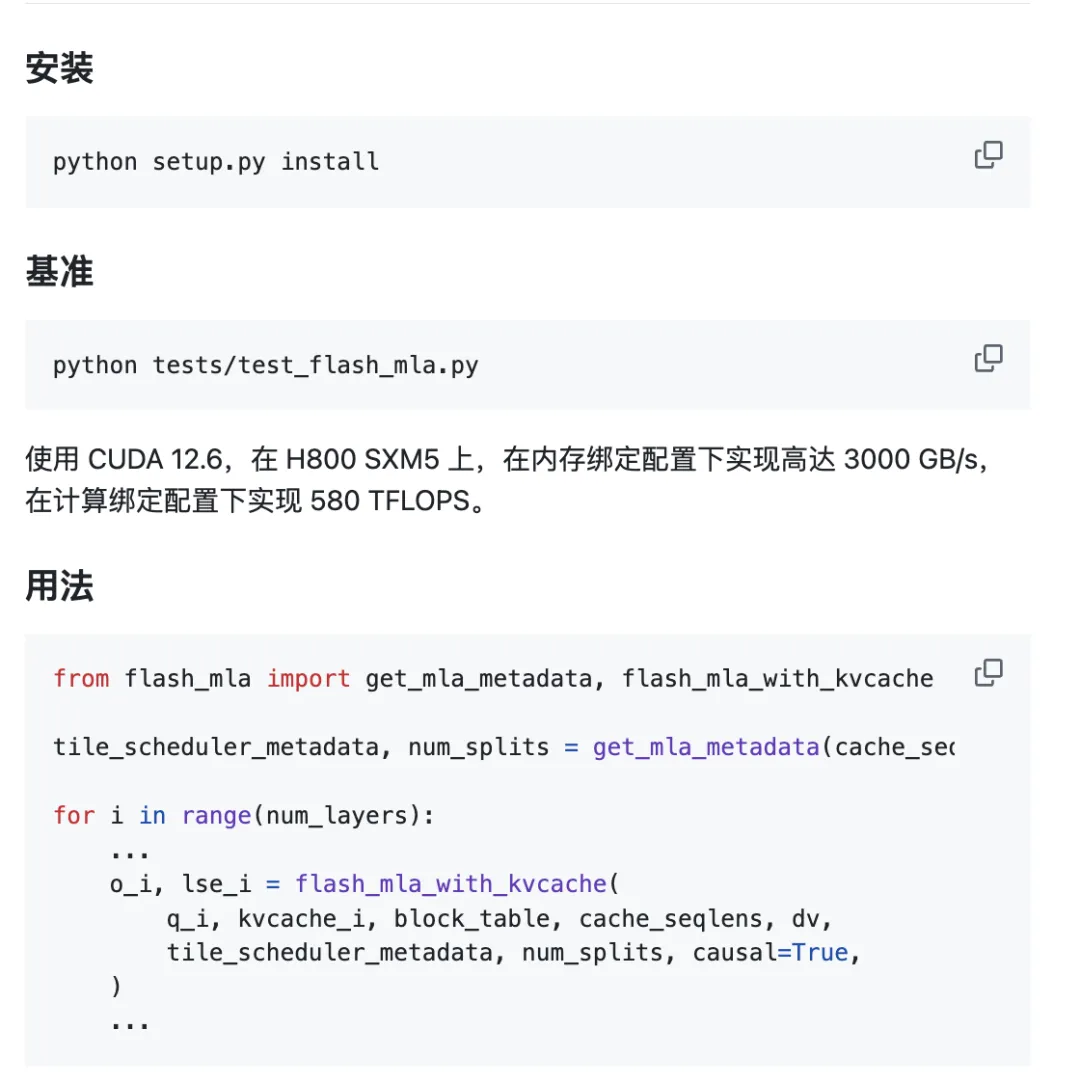
環境要求:
- 料斗 GPU
- CUDA 12.3 及更高版本
- PyTorch 2.0 以上版本
在計畫最後,官方也表示,受到了FlashAttention 2&3和NVIDIA CUTLASS計畫的啟發。

FlashAttention能夠實現快速、節省記憶體的精準注意力,並被主流大模型採用。最新的第三代版本可以將H100的使用率提高到75%。
訓練速度提升1.5-2倍,FP16下計算吞吐高達740 TFLOPs/s,達到理論最大吞吐率75%,更充分利用運算資源,而先前僅為35%。
FlashMLA 不僅透過硬體級優化實現了效能的飛躍,更為AI推理的工程實踐提供了開箱即用的解決方案,成為加速大模型推理的關鍵技術突破。
第一天就有這麼重大的揭露。
我期待接下來四天的開源內容!
正如網友所說:

鯨魚正在掀起波浪!
DeepSeek 太棒了!

