

A múlt héten az DeepSeek bejelentette, hogy a következő héten öt projektet nyit meg forráskóddal:

A netezők azt mondták: „Ezúttal valóban itt van az OpenAI.”
Most érkezett meg az első nyílt forráskódú projekt, ami a következtetések gyorsításával kapcsolatos, a FlashMLA:
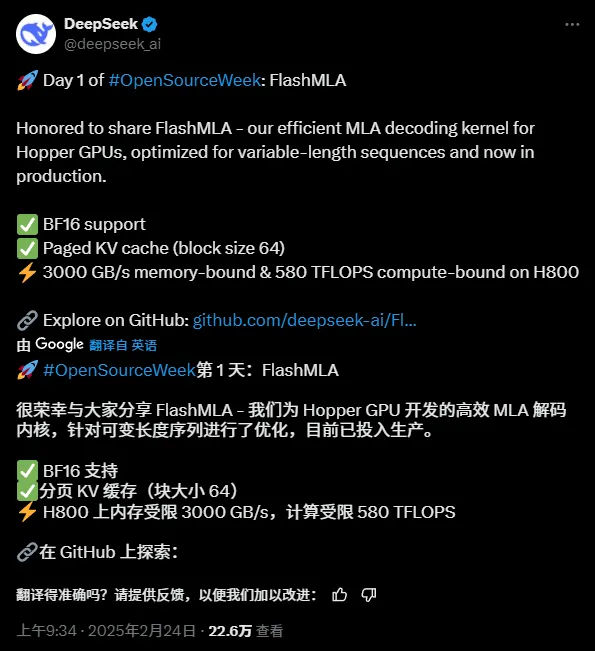
A nyílt forráskódú projekt címe:
Két órája nyílt forráskódú, és a Githubnak már több mint 2,7 ezer csillaga van:
A projekt fő funkciója:
"A FlashMLA egy hatékony MLA dekódoló kernel a Hopper GPU-khoz, változó hosszúságú sorozatok kiszolgálására optimalizálva."
Lefordítva, az:
"A FlashMLA egy hatékony MLA dekódoló kernel, amelyet NVIDIA Hopper architektúrájú GPU-khoz optimalizáltak, és kifejezetten a változó hosszúságú sorozatokat feldolgozó szolgáltatási forgatókönyvekhez optimalizálták."
Dióhéjban:
A FlashMLA egy hatékony dekódoló mag, amelyet a DeepInference fejlesztett ki Hopper architektúrájú GPU-khoz (például a H800-hoz). A változó hosszúságú sorozatok többfejes potenciális figyelem számításának optimalizálásával 3000 GB/s memória sávszélességet és 580TFLOPS számítási teljesítményt ér el a dekódolási szakaszban, jelentősen javítva a hosszú kontextusokkal való érvelés hatékonyságát nagy modellek esetén.
Néhány netező azt mondta:

Vannak, akik már használják, és azt mondják, Pure engineering:
Ez a projekt a mérnöki optimalizálás és szorítja a hardver teljesítményét a határ.
A projekt a dobozból kivéve használatra kész.
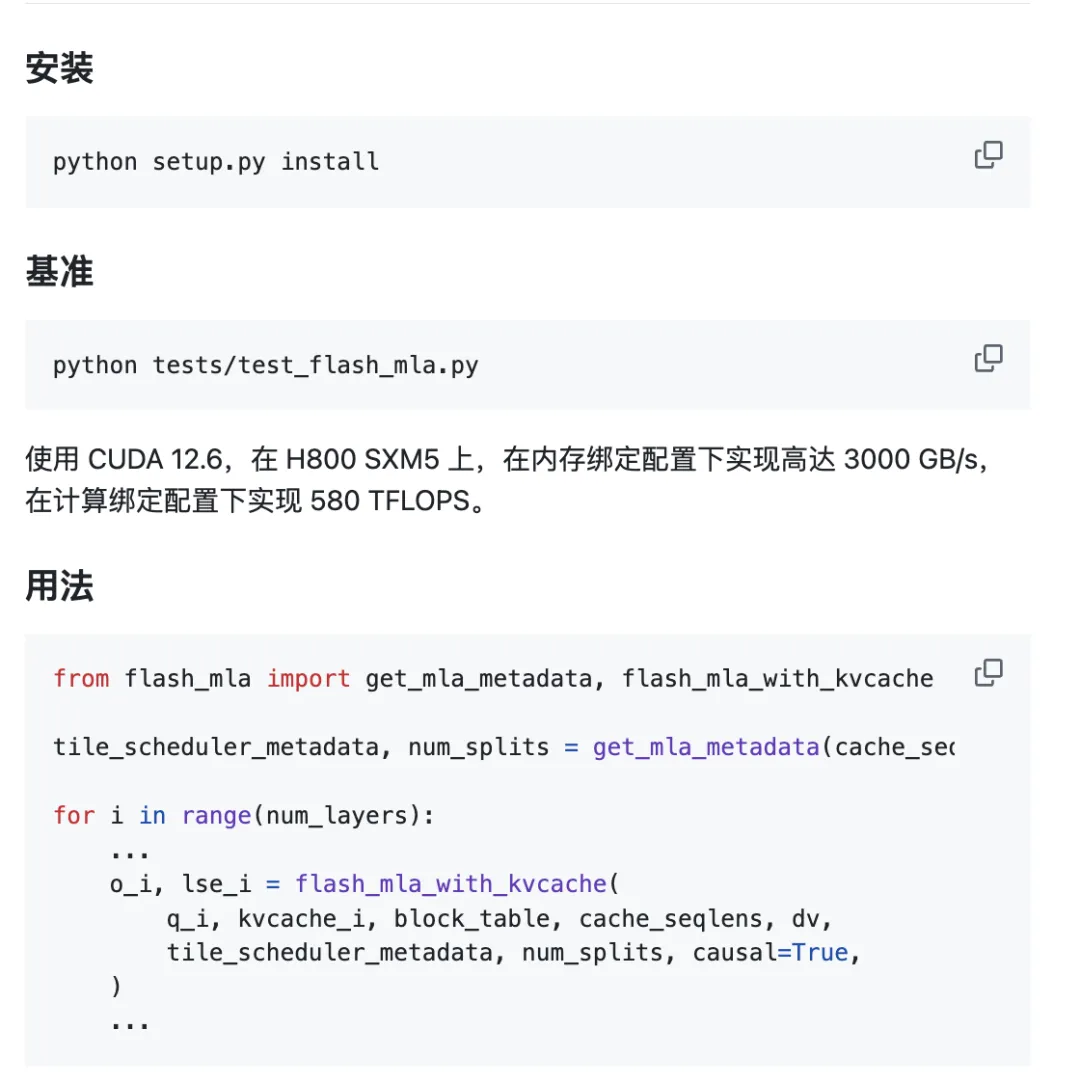
Környezeti követelmények:
- Hopper GPU
- CUDA 12.3 és újabb
- PyTorch 2.0 és újabb
A projekt végén a tisztviselő azt is kijelentette, hogy a FlashAttention 2&3 és az NVIDIA CUTLASS projektek ihlették.

A FlashAttention gyors és memória-hatékony precíz figyelem elérésére képes, és a mainstream nagy modellekben használatos. A legújabb, harmadik generációs verzió 75%-re növelheti a H100 kihasználtságát.
A képzési sebesség 1,5-2-szeresére nő, az FP16 számítási teljesítménye pedig eléri a 740 TFLOP/s-ot, ami eléri az elméleti maximális átviteli sebesség 75%-ját, és teljesebben kihasználja a számítási erőforrásokat, ami korábban csak 35% volt.
FlashMLA A hardverszintű optimalizálással nemcsak teljesítményugrást ér el, hanem kész megoldást is kínál a mesterséges intelligencia-következtetés mérnöki gyakorlataihoz, és kulcsfontosságú technológiai áttörést jelent a nagy modellek következtetéseinek felgyorsításában.
Volt egy nagy leleplezés az első napon.
Várom a nyílt forráskódú cuccokat a következő négy napban!
Ahogy a netező mondta:

A bálna hullámokat ver!
Az DeepSeek fantasztikus!

