

W zeszłym tygodniu DeepSeek ogłosiło, że w przyszłym tygodniu udostępni kod źródłowy pięciu projektów:

Internauci stwierdzili: „Tym razem OpenAI naprawdę nadeszło”.
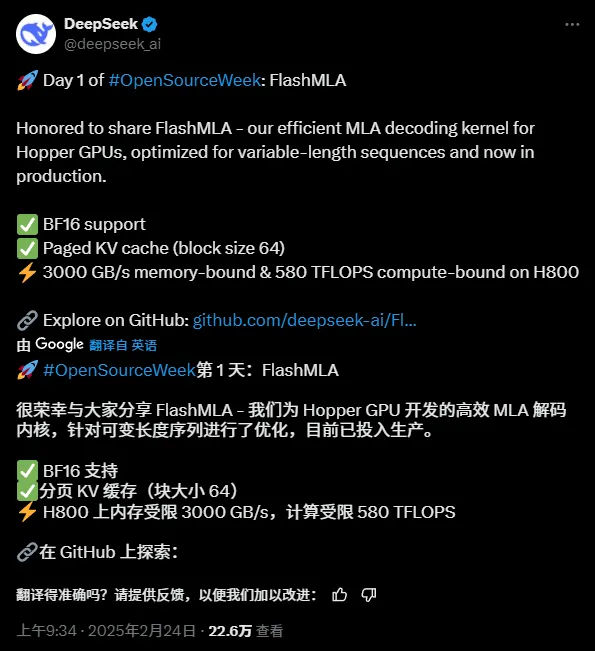
Właśnie pojawił się pierwszy projekt typu open source związany z przyspieszeniem wnioskowania, FlashMLA:
Adres projektu Open Source:
Jest on dostępny jako oprogramowanie open source od dwóch godzin, a Github ma już ponad 2,7 tys. gwiazdek:
Podstawową funkcją projektu jest:
„FlashMLA to wydajne jądro dekodujące MLA dla procesorów graficznych Hopper, zoptymalizowane pod kątem obsługi sekwencji o zmiennej długości”.
Przetłumaczone, to jest:
„FlashMLA to wydajne jądro dekodujące MLA zoptymalizowane pod kątem procesorów graficznych z architekturą NVIDIA Hopper, specjalnie zoptymalizowane pod kątem scenariuszy usługowych, w których przetwarzane są sekwencje o zmiennej długości”.
W paru słowach:
FlashMLA to wydajny rdzeń dekodujący zaprojektowany przez DeepInference dla procesorów graficznych Hopper-architecture (takich jak H800). Dzięki optymalizacji wielogłowicowego potencjalnego obliczenia uwagi sekwencji o zmiennej długości osiąga on najwyższą wydajność 3000 GB/s przepustowości pamięci i 580 TFLOPS mocy obliczeniowej na etapie dekodowania, znacznie poprawiając wydajność rozumowania z długimi kontekstami dla dużych modeli.
Niektórzy internauci powiedzieli:

Niektórzy ludzie już z tego korzystają i twierdzą, że to czysta inżynieria:
Projekt ten należy do dziedziny optymalizacji inżynieryjnej i ściska wydajność sprzętu do maksimum limit.
Projekt jest gotowy do użycia od razu po wyjęciu z pudełka.
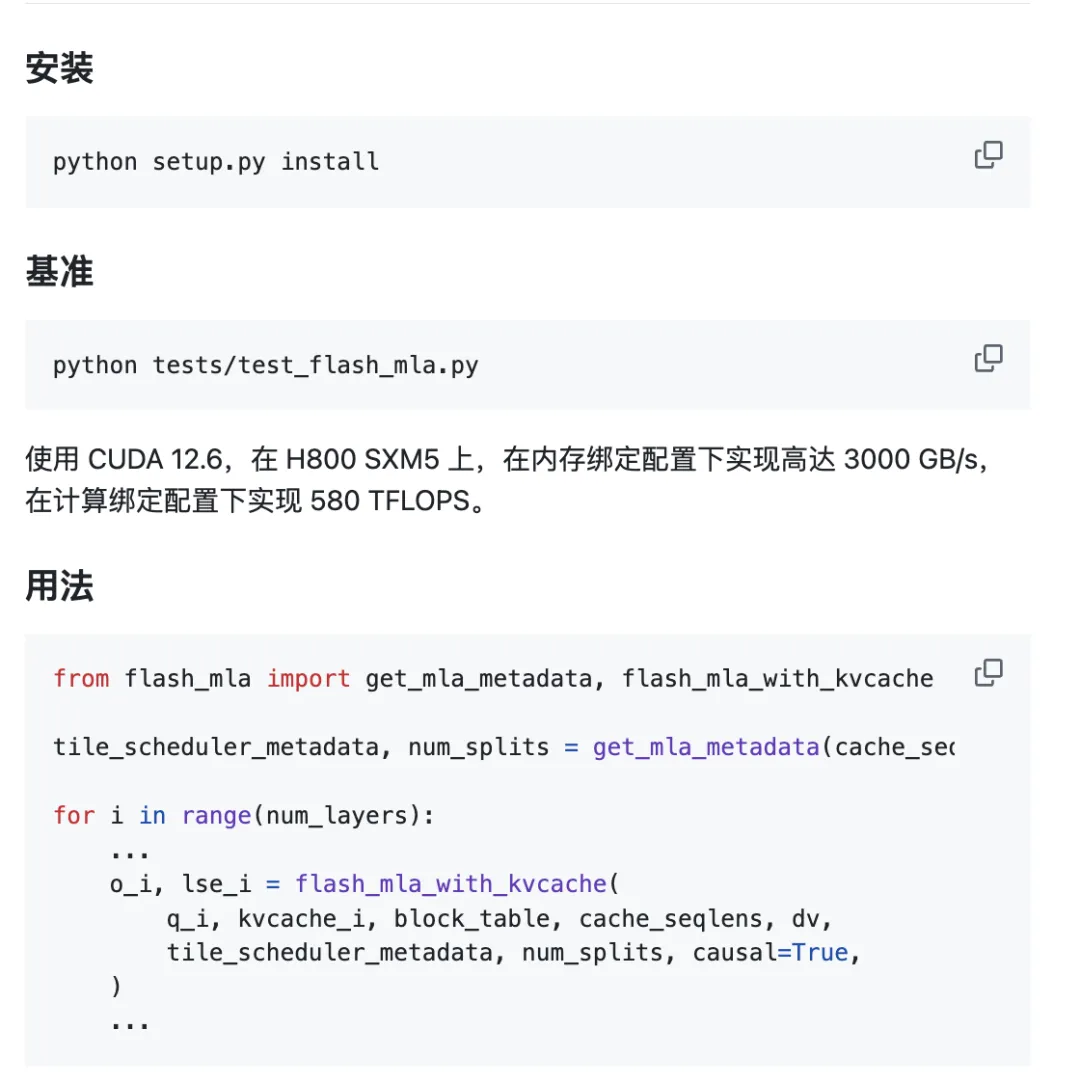
Wymagania środowiskowe:
- Procesor graficzny Hoppera
- CUDA 12.3 i nowsze
- PyTorch 2.0 i nowsze
Pod koniec projektu urzędnik stwierdził także, że inspiracją były projekty FlashAttention 2&3 oraz NVIDIA CUTLASS.

FlashAttention jest w stanie osiągnąć szybką i wydajną pod względem pamięci precyzyjną uwagę i jest używany w popularnych dużych modelach. Najnowsza wersja trzeciej generacji może zwiększyć wskaźnik wykorzystania H100 do 75%.
Prędkość treningu wzrasta 1,5-2 razy, a przepustowość obliczeniowa w ramach FP16 sięga aż 740 TFLOPs/s, osiągając 75% teoretycznej maksymalnej przepustowości i umożliwiając pełniejsze wykorzystanie zasobów obliczeniowych, które wcześniej wynosiły zaledwie 35%.
BłyskMLA nie tylko zapewnia skokowy wzrost wydajności dzięki optymalizacji na poziomie sprzętowym, ale także stanowi gotowe rozwiązanie dla praktyk inżynieryjnych w zakresie wnioskowania AI, stając się kluczowym przełomem technologicznym w przyspieszaniu wnioskowania dużych modeli.
Pierwszego dnia nastąpiło wielkie odkrycie.
Z niecierpliwością czekam na nowości open source, które pojawią się w ciągu najbliższych czterech dni!
Jak powiedział internauta:

Wieloryb wywołuje fale!
DeepSeek jest niesamowity!


