

La semaine dernière, DeepSeek a annoncé qu'il ouvrirait le code source de cinq projets la semaine prochaine :

Les internautes ont déclaré : « Cette fois, OpenAI est vraiment là. »
Tout juste sorti le premier projet open source lié à l'accélération de l'inférence, FlashMLA :
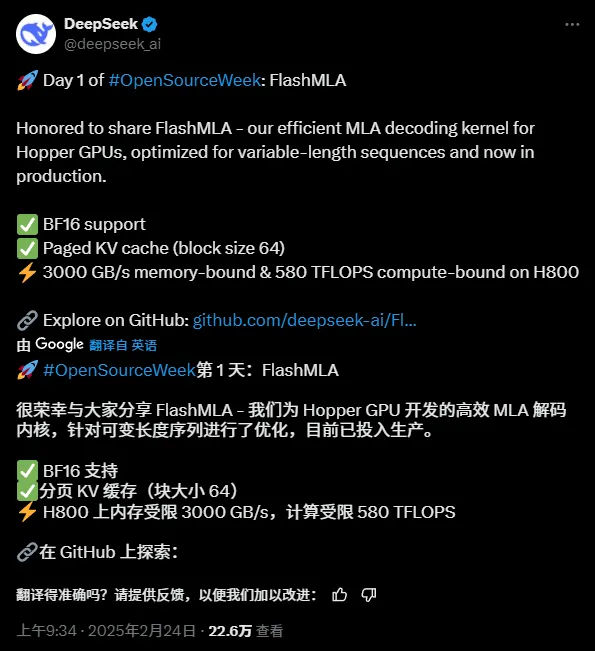
Adresse du projet open source :
Il est open source depuis deux heures et Github compte déjà plus de 2,7 000 étoiles :
La fonction principale du projet est :
« FlashMLA est un noyau de décodage MLA efficace pour les GPU Hopper, optimisé pour la diffusion de séquences de longueur variable. »
Traduit, c'est:
« FlashMLA est un noyau de décodage MLA efficace optimisé pour les GPU d'architecture NVIDIA Hopper, spécifiquement optimisé pour les scénarios de service qui traitent des séquences de longueur variable. »
En un mot:
FlashMLA est un cœur de décodage efficace conçu par DeepInference pour les GPU à architecture Hopper (comme le H800). En optimisant le calcul d'attention potentielle multi-têtes de séquences de longueur variable, il atteint les performances ultimes de 3000 Go/s de bande passante mémoire et de 580 TFLOPS de puissance de calcul dans l'étape de décodage, améliorant considérablement l'efficacité du raisonnement avec des contextes longs pour les grands modèles.
Certains internautes ont déclaré :

Certaines personnes l'utilisent déjà et disent que c'est de l'ingénierie pure :
Ce projet appartient à l'optimisation de l'ingénierie et comprime les performances matérielles au maximum limite.
Le projet est prêt à l'emploi.
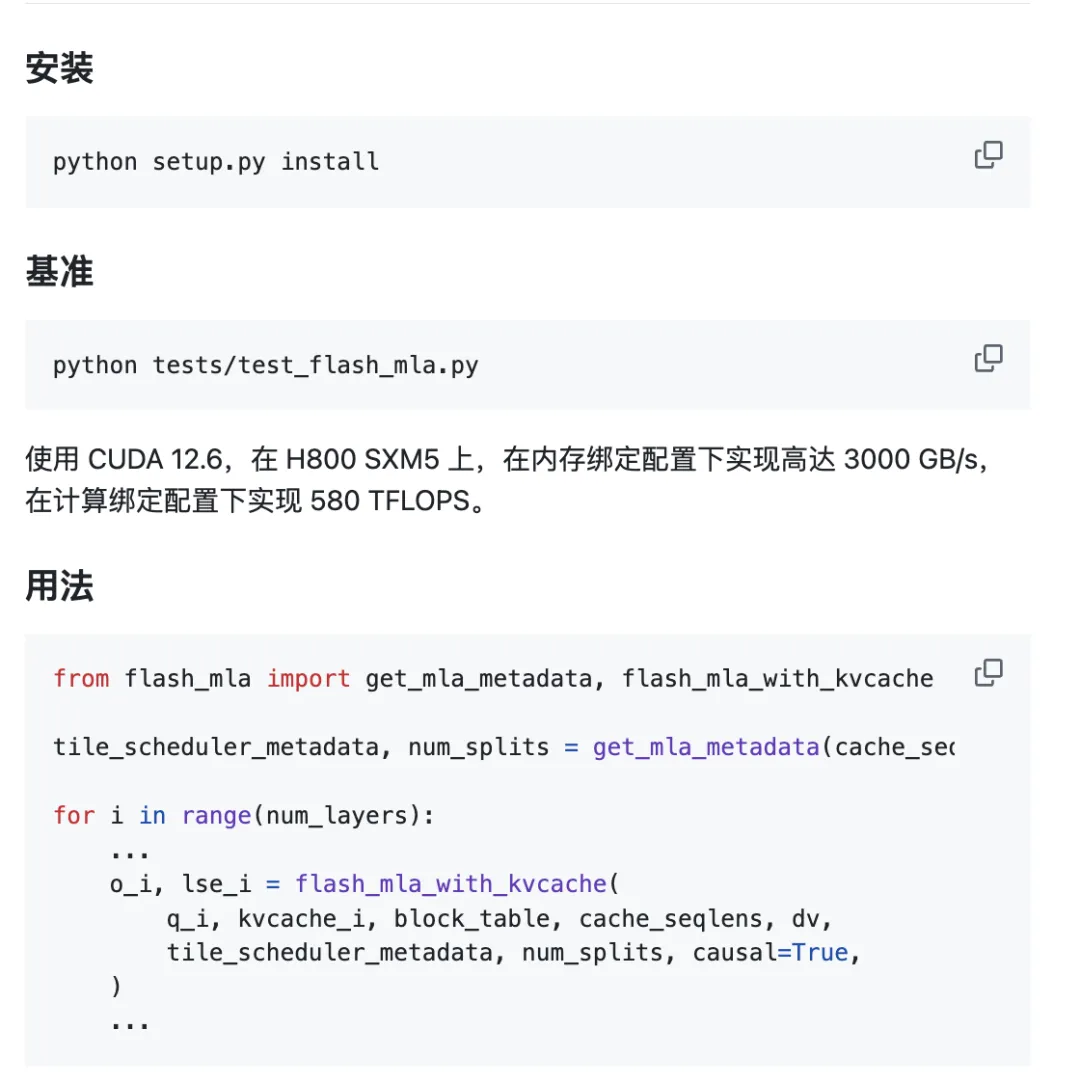
Exigences environnementales :
- Trémie GPU
- CUDA 12.3 et versions ultérieures
- PyTorch 2.0 et versions ultérieures
À la fin du projet, le responsable a également déclaré qu'il s'inspirait des projets FlashAttention 2&3 et NVIDIA CUTLASS.

FlashAttention est capable d'atteindre une attention précise rapide et efficace en termes de mémoire et est utilisé dans les grands modèles grand public. La dernière version de troisième génération peut augmenter le taux d'utilisation du H100 à 75%.
La vitesse de formation est augmentée de 1,5 à 2 fois et le débit de calcul sous FP16 atteint 740 TFLOPs/s, atteignant 75% du débit maximal théorique et utilisant plus pleinement les ressources de calcul, qui n'étaient auparavant que de 35%.
FlashMLA non seulement réalise un bond en avant en termes de performances grâce à l'optimisation au niveau du matériel, mais fournit également une solution prête à l'emploi pour les pratiques d'ingénierie en matière d'inférence d'IA, devenant ainsi une avancée technologique clé dans l'accélération de l'inférence de grands modèles.
Il y a eu une telle révélation le premier jour.
J'attends avec impatience les nouveautés open source dans les quatre prochains jours !
Comme l'a dit l'internaute :

La baleine fait des vagues !
DeepSeek est génial !



