

Förra veckan meddelade DeepSeek att det skulle öppna källkod för fem projekt nästa vecka:

Netizens sa: "Den här gången är OpenAI verkligen här."
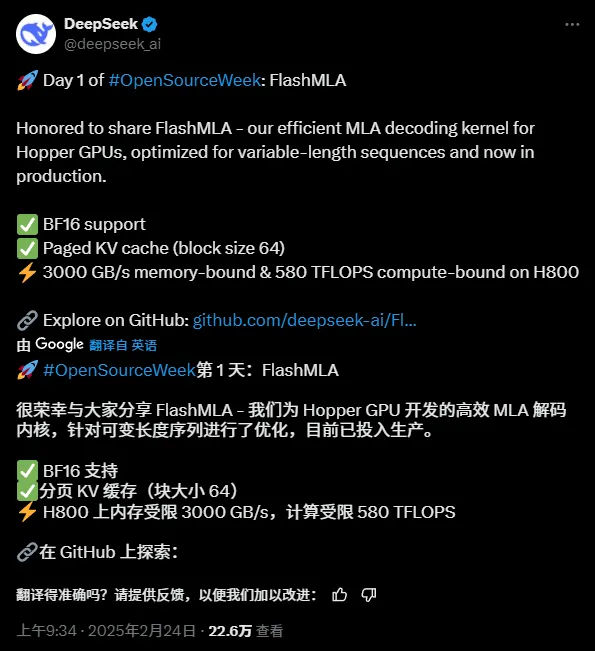
Just nu kom det första open source-projektet, relaterat till inferensacceleration, FlashMLA:
Öppen källkod projektadress:
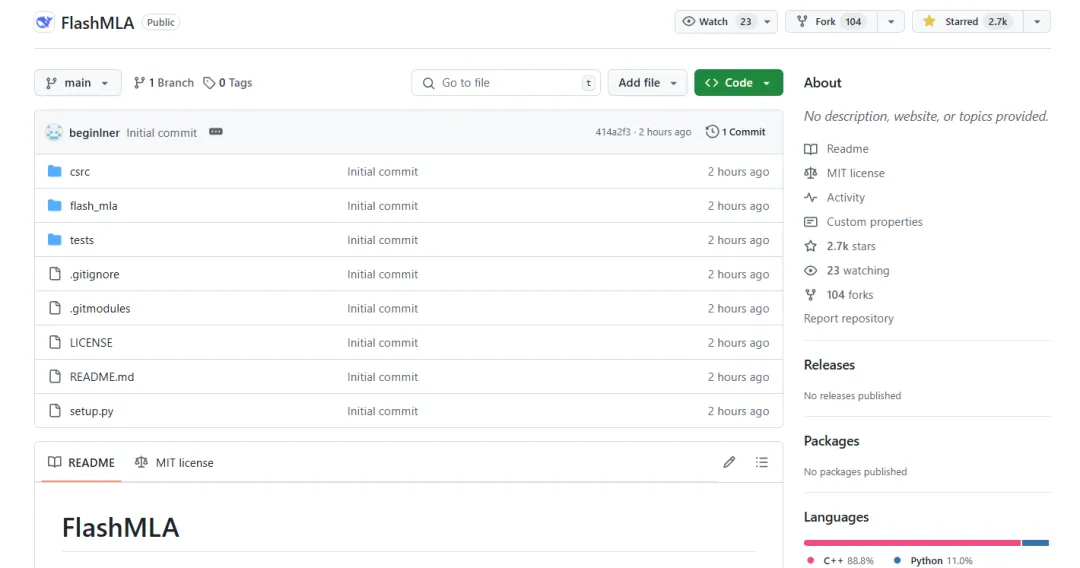
Det har varit öppen källkod i två timmar, och Github har redan 2,7k+ stjärnor:
Projektets kärnfunktion är:
"FlashMLA är en effektiv MLA-avkodningskärna för Hopper GPU:er, optimerad för sekvenser med variabel längd."
Översatt är det:
"FlashMLA är en effektiv MLA-avkodningskärna optimerad för NVIDIA Hopper-arkitektur-GPU:er, specifikt optimerad för tjänstescenarier som bearbetar sekvenser med variabel längd."
I korthet:
FlashMLA är en effektiv avkodningskärna designad av DeepInference för Hopper-arkitektur GPU:er (som H800). Genom att optimera den potentiella uppmärksamhetsberäkningen för flera huvuden av sekvenser med variabel längd, uppnår den den ultimata prestandan på 3000 GB/s minnesbandbredd och 580 TFLOPS beräkningskraft i avkodningssteget, vilket avsevärt förbättrar effektiviteten av resonemang med långa sammanhang för stora modeller.
Några nätanvändare sa:

Vissa människor använder det redan, och de säger Ren ingenjörskonst:
Detta projekt tillhör ingenjörsoptimering och pressar hårdvarans prestanda till begränsa.
Projektet är klart att användas direkt.
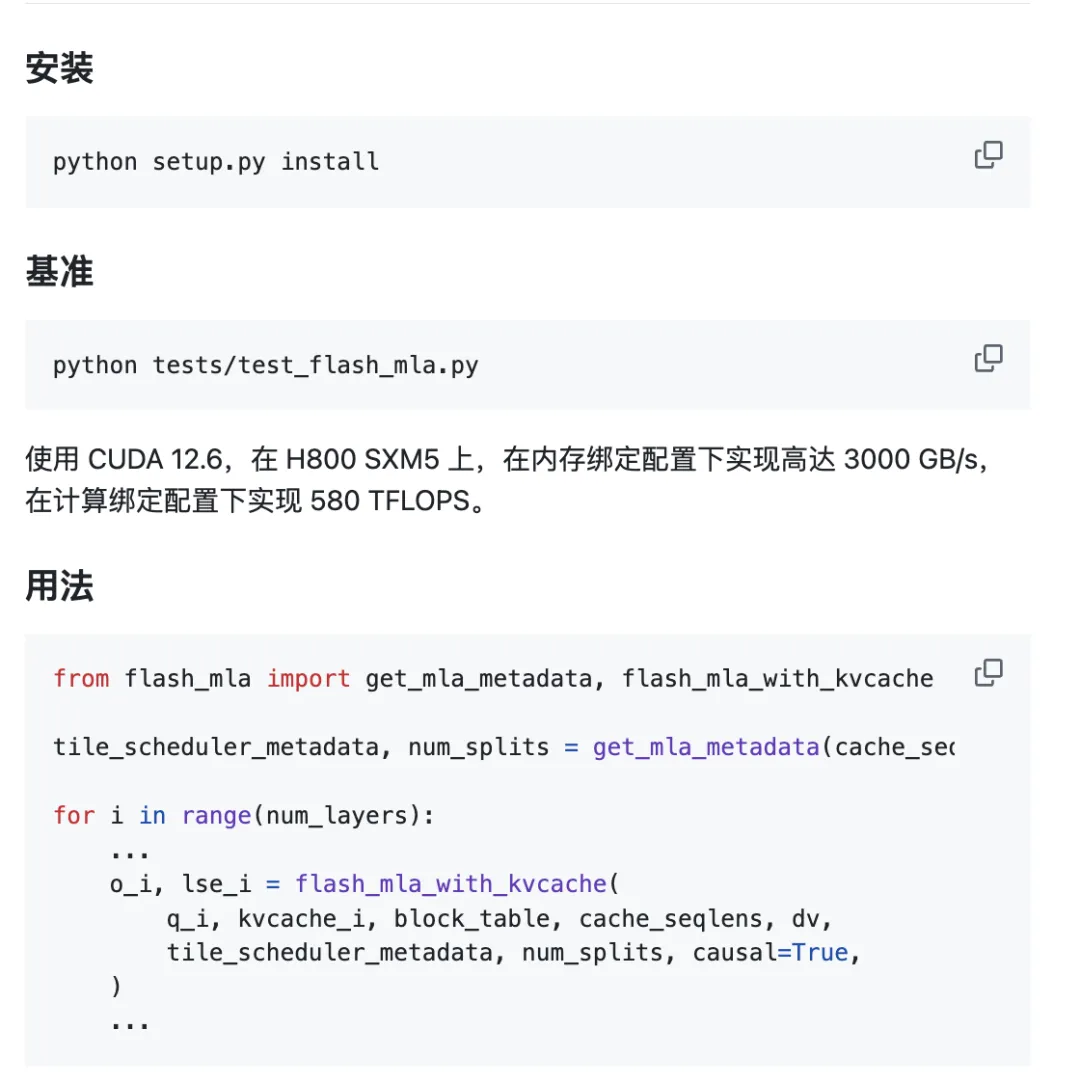
Miljökrav:
- Hopper GPU
- CUDA 12.3 och högre
- PyTorch 2.0 och senare
I slutet av projektet uppgav tjänstemannen också att det var inspirerat av FlashAttention 2&3- och NVIDIA CUTLASS-projekten.

FlashAttention kan uppnå snabb och minneseffektiv exakt uppmärksamhet och används i vanliga stora modeller. Den senaste tredje generationens version kan öka utnyttjandegraden för H100 till 75%.
Träningshastigheten ökas med 1,5-2 gånger, och beräkningsgenomströmningen under FP16 är så hög som 740 TFLOPs/s, och når 75% av den teoretiska maximala genomströmningen och utnyttjar beräkningsresurserna fullt ut, som tidigare bara var 35%.
FlashMLA uppnår inte bara ett språng i prestanda genom optimering på hårdvarunivå, utan tillhandahåller också en färdig lösning för teknisk praxis inom AI-inferens, vilket blir ett nyckelteknologiskt genombrott för att accelerera slutledning av stora modeller.
Det var en så stor avslöjande den första dagen.
Jag ser fram emot grejer med öppen källkod under de kommande fyra dagarna!
Som nätanvändaren sa:

Valen gör vågor!
DeepSeek är fantastiskt!


