

ባለፈው ሳምንት፣ DeepSeek በሚቀጥለው ሳምንት አምስት ፕሮጀክቶችን እንደሚከፍት አስታውቋል፡-

Netizens “በዚህ ጊዜ OpenAI በእርግጥ እዚህ አለ።
ልክ አሁን፣ የመጀመሪያው ክፍት ምንጭ ፕሮጀክት መጣ፣ ከግንዛቤ ማጣደፍ፣ FlashMLA፡
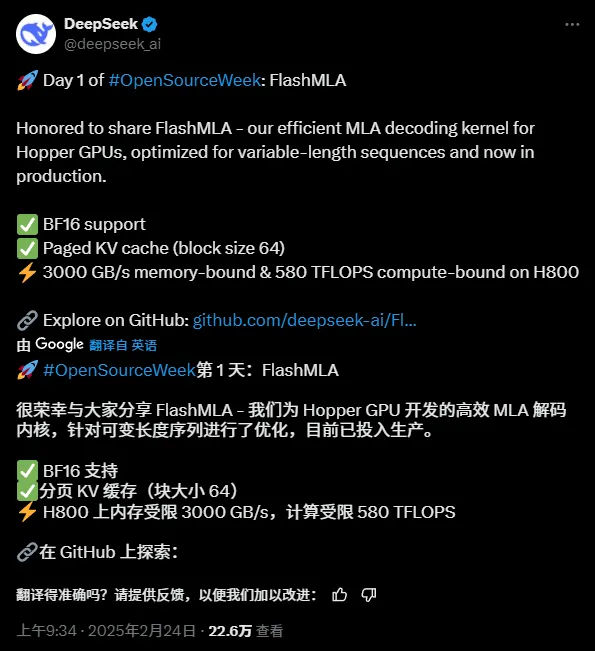
ክፍት ምንጭ የፕሮጀክት አድራሻ፡-
ለሁለት ሰዓታት ክፍት ምንጭ ሆኖ ቆይቷል፣ እና Github ቀድሞውንም 2.7k+ ኮከቦች አሉት።
የፕሮጀክቱ ዋና ተግባር፡-
"FlashMLA ለሆፐር ጂፒዩዎች ቀልጣፋ የኤምኤልኤ ዲኮዲንግ ከርነል ነው፣ ለተለዋዋጭ ርዝመት ተከታታይ አገልግሎት የተመቻቸ።"
ነው የተተረጎመው:
"FlashMLA ለNVadi Hopper architecture GPUs የተመቻቸ ቀልጣፋ የኤምኤልኤ ዲኮዲንግ ከርነል ነው፣በተለይ ተለዋዋጭ ርዝመት ቅደም ተከተሎችን ለሚያስኬዱ የአገልግሎት ሁኔታዎች የተመቻቸ ነው።"
ባጭሩ፡-
FlashMLA በ DeepInference የተነደፈ ቀልጣፋ ዲኮዲንግ ኮር ነው ለሆፐር-አርክቴክቸር ጂፒዩዎች (እንደ H800)። የብዝሃ-ጭንቅላት እምቅ ትኩረት ስሌትን በተለዋዋጭ ርዝመት ቅደም ተከተሎች በማመቻቸት የ3000GB/s የማህደረ ትውስታ ባንድዊድዝ እና 580TFLOPS የማስላት ሃይል በመፍታት ደረጃ የመጨረሻውን አፈጻጸም ያሳካል፣ይህም ለትልቅ ሞዴሎች ከረዥም አውዶች ጋር የማመዛዘን ቅልጥፍናን በእጅጉ ያሻሽላል።
አንዳንድ መረቦች እንዲህ አሉ።

አንዳንድ ሰዎች ቀድሞውንም እየተጠቀሙበት ነው፣ እና ንጹህ ምህንድስና ይላሉ፡-
ይህ ፕሮጀክት የምህንድስና ማመቻቸት እና ነው። የሃርድዌር አፈፃፀሙን ወደ ገደብ.
ፕሮጀክቱ ከሳጥኑ ውጭ ለመጠቀም ዝግጁ ነው.
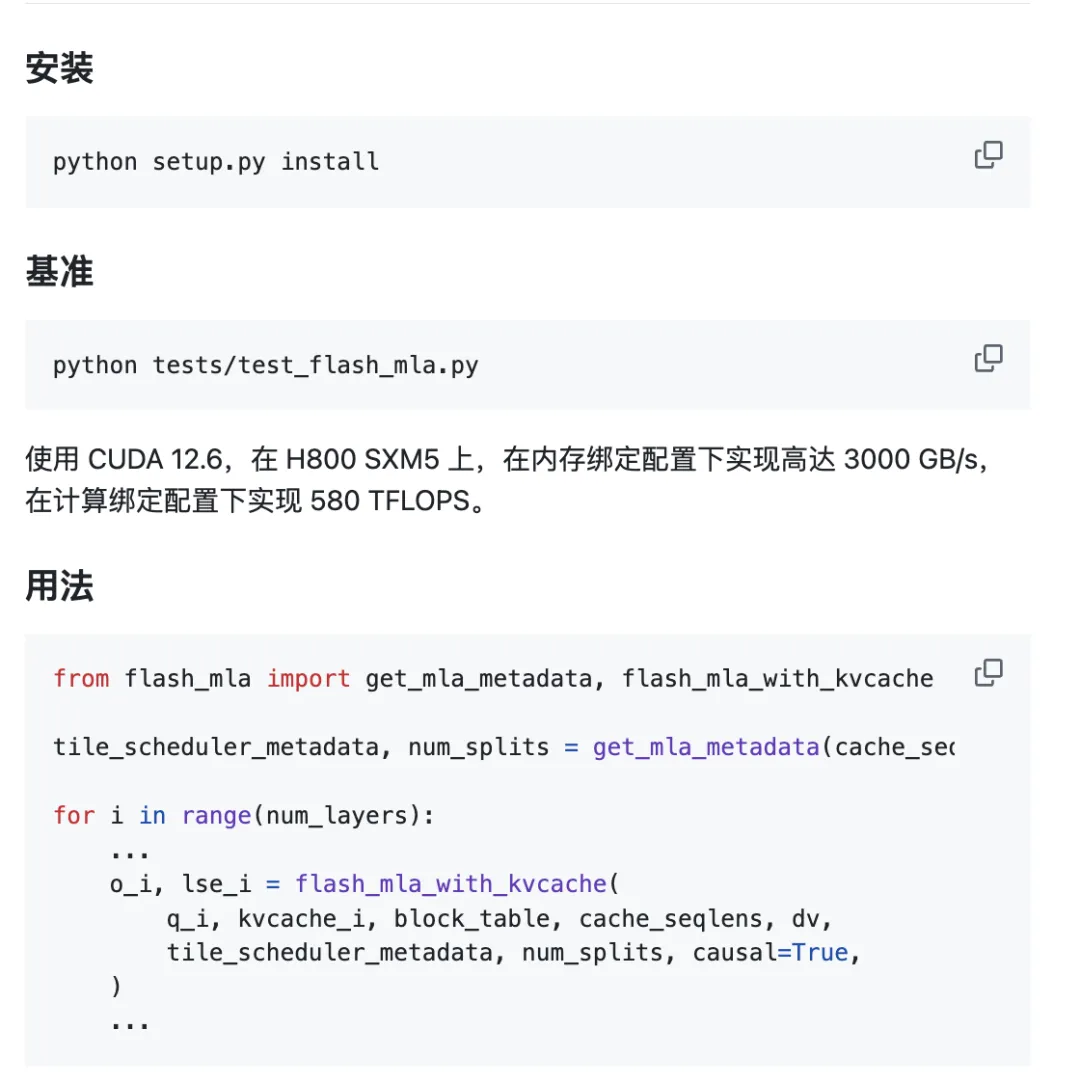
የአካባቢ መስፈርቶች:
- ሆፐር ጂፒዩ
- CUDA 12.3 እና ከዚያ በላይ
- ፒቶርች 2.0 እና ከዚያ በላይ
በፕሮጀክቱ መጨረሻ ላይ ባለሥልጣኑ በ FlashAttention 2&3 እና በNVadi CUTLASS ፕሮጄክቶች መነሳሳቱን ገልጿል።

FlashAttention ፈጣን እና የማስታወስ ብቃት ያለው ትክክለኛ ትኩረት የማግኘት ችሎታ አለው፣ እና በዋና ትላልቅ ሞዴሎች ውስጥ ጥቅም ላይ ይውላል። የመጨረሻው የሶስተኛ-ትውልድ ስሪት የH100 አጠቃቀምን መጠን ወደ 75% ሊጨምር ይችላል።
የሥልጠና ፍጥነት በ1.5-2 ጊዜ ጨምሯል፣ እና በ FP16 ያለው የስሌት መጠን እስከ 740 TFLOPs/s ከፍ ያለ ሲሆን ከቲዎሬቲካል ከፍተኛው የውጤት መጠን 75% በመድረስ እና የኮምፒዩተር ግብዓቶችን በተሟላ ሁኔታ መጠቀም፣ ይህም ቀደም ሲል 35% ብቻ ነበር።
FlashMLA በሃርድዌር-ደረጃ ማመቻቸት አፈጻጸም ላይ አንድ ዝላይ ማሳካት ብቻ ሳይሆን ከሳጥን ውጭ የሆነ የምህንድስና ልምምዶችን በ AI ኢንፈረንስ ያቀርባል፣ ይህም ትላልቅ ሞዴሎችን ፍንጭ በማፍጠን ረገድ ቁልፍ የቴክኖሎጂ ግኝቶች ይሆናል።
በመጀመሪያው ቀን እንደዚህ ያለ ትልቅ መገለጥ ነበር.
በሚቀጥሉት አራት ቀናት ውስጥ የክፍት ምንጭ ነገሮችን በጉጉት እጠብቃለሁ!
መረቡ እንደተናገረው፡-

ዓሣ ነባሪው ማዕበል እየፈጠረ ነው!
DeepSeek ግሩም ነው!

