

গত সপ্তাহে, DeepSeek ঘোষণা করেছে যে তারা আগামী সপ্তাহে পাঁচটি প্রকল্প ওপেন সোর্স করবে:

নেটিজেনরা বলেছেন, "এবার, ওপেনএআই সত্যিই এখানে।"
এইমাত্র, প্রথম ওপেন সোর্স প্রকল্পটি এসেছে, যা ইনফারেন্স অ্যাক্সিলারেশন সম্পর্কিত, FlashMLA:
ওপেন সোর্স প্রকল্পের ঠিকানা:
এটি দুই ঘন্টা ধরে ওপেন সোর্স হিসেবে কাজ করছে, এবং Github ইতিমধ্যেই ২.৭ হাজারেরও বেশি তারকা পেয়েছে:
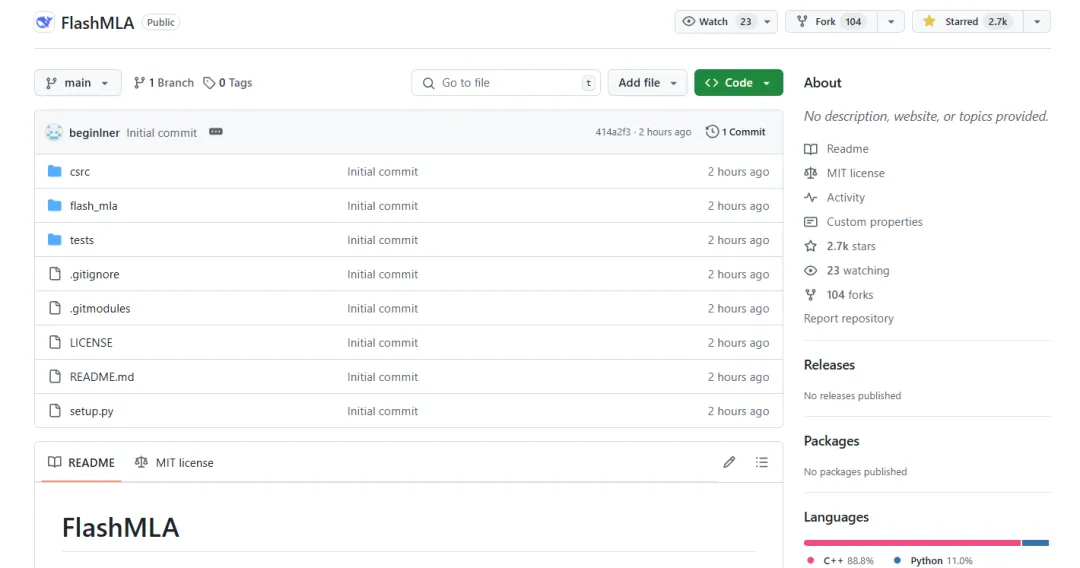
প্রকল্পের মূল কাজ হল:
"FlashMLA হল Hopper GPU-এর জন্য একটি দক্ষ MLA ডিকোডিং কার্নেল, যা ভেরিয়েবল-লেংথ সিকোয়েন্স পরিবেশনের জন্য অপ্টিমাইজ করা হয়েছে।"
অনুবাদিত, এটি হল:
"FlashMLA হল একটি দক্ষ MLA ডিকোডিং কার্নেল যা NVIDIA Hopper আর্কিটেকচার GPU-এর জন্য অপ্টিমাইজ করা হয়েছে, বিশেষ করে এমন পরিষেবা পরিস্থিতির জন্য অপ্টিমাইজ করা হয়েছে যা পরিবর্তনশীল-দৈর্ঘ্যের ক্রম প্রক্রিয়া করে।"
সংক্ষেপে:
FlashMLA হল একটি দক্ষ ডিকোডিং কোর যা DeepInference দ্বারা Hopper-আর্কিটেকচার GPU-এর জন্য ডিজাইন করা হয়েছে (যেমন H800)। পরিবর্তনশীল-দৈর্ঘ্যের সিকোয়েন্সের মাল্টি-হেড পটেনশিয়াল অ্যাটেনশন ক্যালকুলেশন অপ্টিমাইজ করে, এটি ডিকোডিং পর্যায়ে 3000GB/s মেমরি ব্যান্ডউইথ এবং 580TFLOPS কম্পিউটিং পাওয়ারের চূড়ান্ত কর্মক্ষমতা অর্জন করে, যা বৃহৎ মডেলগুলির জন্য দীর্ঘ প্রেক্ষাপটের সাথে যুক্তির দক্ষতা উল্লেখযোগ্যভাবে উন্নত করে।
কিছু নেটিজেন বলেছেন:

কিছু লোক ইতিমধ্যেই এটি ব্যবহার করছে, এবং তারা বলে পিওর ইঞ্জিনিয়ারিং:
এই প্রকল্পটি ইঞ্জিনিয়ারিং অপ্টিমাইজেশনের অন্তর্গত এবং হার্ডওয়্যারের কর্মক্ষমতাকে এমনভাবে চেপে ধরে যে সীমা।
প্রকল্পটি সম্পূর্ণরূপে ব্যবহারের জন্য প্রস্তুত।
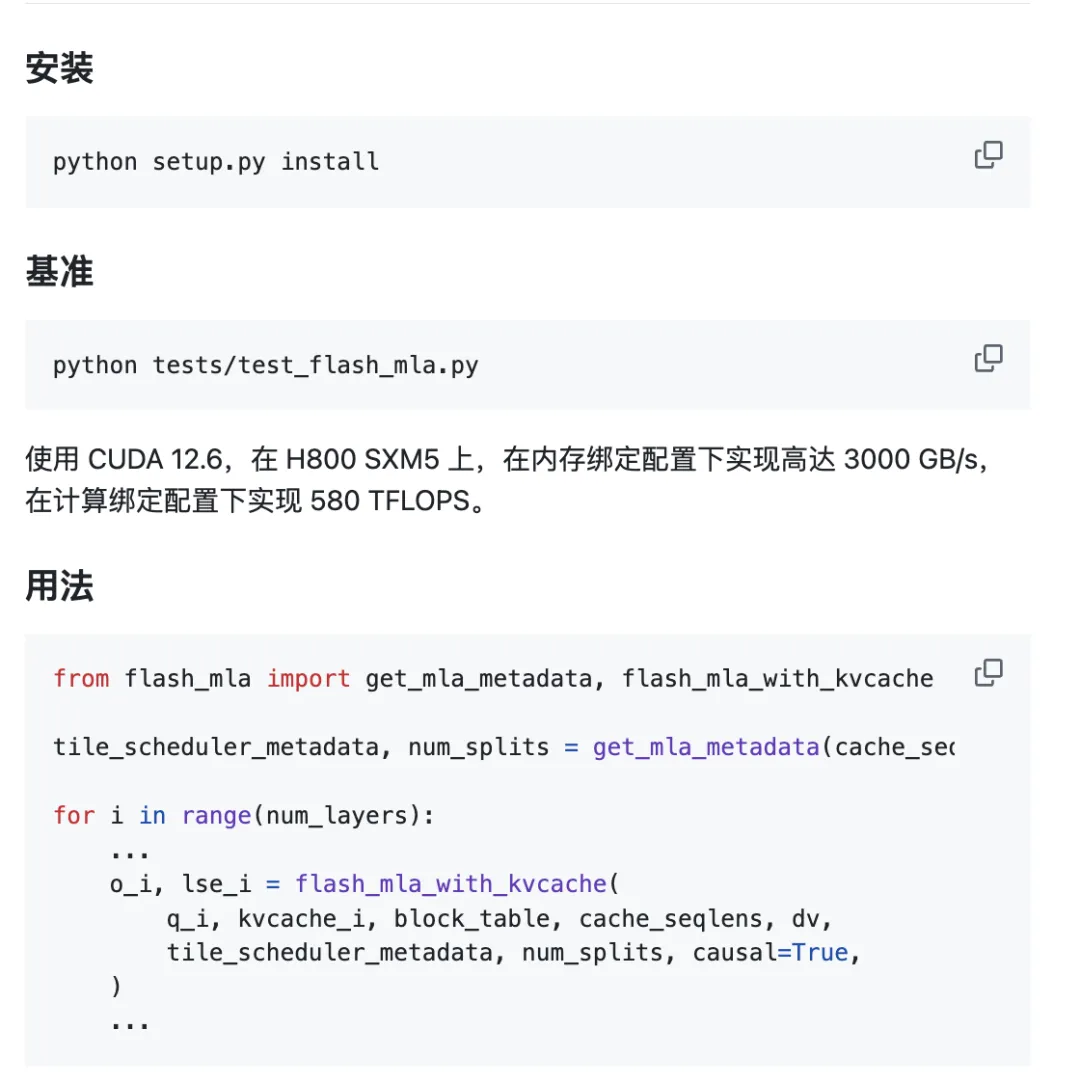
পরিবেশগত প্রয়োজনীয়তা:
- হপার জিপিইউ
- CUDA ১২.৩ এবং তার উপরে
- পাইটর্চ ২.০ এবং তার উপরে
প্রকল্পের শেষে, কর্মকর্তা আরও বলেন যে এটি FlashAttention 2&3 এবং NVIDIA CUTLASS প্রকল্প দ্বারা অনুপ্রাণিত।

FlashAttention দ্রুত এবং স্মৃতি-দক্ষ সুনির্দিষ্ট মনোযোগ অর্জন করতে সক্ষম, এবং মূলধারার বৃহৎ মডেলগুলিতে ব্যবহৃত হয়। সর্বশেষ তৃতীয়-প্রজন্মের সংস্করণটি H100 এর ব্যবহারের হার 75%-তে বৃদ্ধি করতে পারে।
প্রশিক্ষণের গতি ১.৫-২ গুণ বৃদ্ধি করা হয়েছে, এবং FP16 এর অধীনে গণনামূলক থ্রুপুট ৭৪০ TFLOPs/s পর্যন্ত, যা তাত্ত্বিক সর্বোচ্চ থ্রুপুটের ৭৫১TP11T এ পৌঁছায় এবং কম্পিউটিং সংস্থানগুলির পূর্ণ ব্যবহার করা হয়েছে, যা আগে মাত্র ৩৫১TP11T ছিল।
FlashMLA সম্পর্কে হার্ডওয়্যার-স্তরের অপ্টিমাইজেশনের মাধ্যমে কেবল কর্মক্ষমতায় উল্লম্ফনই অর্জন করে না, বরং এআই ইনফারেন্সে ইঞ্জিনিয়ারিং অনুশীলনের জন্য একটি বহিরাগত সমাধানও প্রদান করে, যা বৃহৎ মডেলের ইনফারেন্স ত্বরান্বিত করার ক্ষেত্রে একটি গুরুত্বপূর্ণ প্রযুক্তিগত অগ্রগতি হয়ে ওঠে।
প্রথম দিনেই এত বড় একটা তথ্য প্রকাশ পেল।
আমি আগামী চার দিনের মধ্যে ওপেন সোর্স স্টাফের জন্য অপেক্ষা করছি!
যেমনটি নেটিজেন বলেছেন:

তিমিটি ঢেউ তুলছে!
DeepSeek অসাধারণ!



