

La semana pasada, DeepSeek anunció que la próxima semana abrirá el código fuente de cinco proyectos:

Los internautas dijeron: “Esta vez, OpenAI realmente está aquí”.
Hace poco apareció el primer proyecto de código abierto relacionado con la aceleración de inferencias, FlashMLA:
Dirección del proyecto de código abierto:
Ha sido de código abierto durante dos horas y Github ya tiene más de 2.700 estrellas:
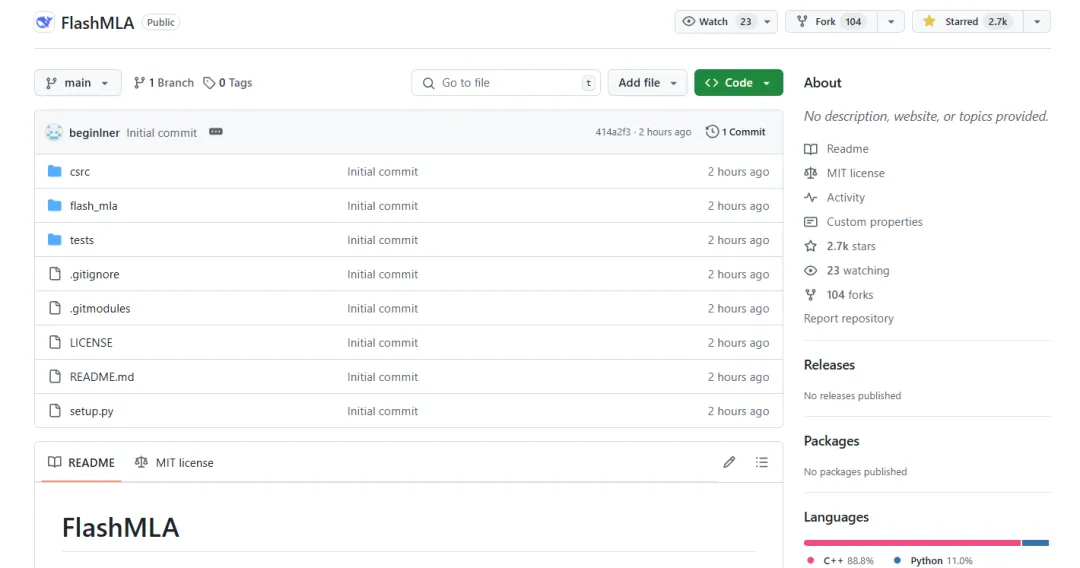
La función principal del proyecto es:
“FlashMLA es un núcleo de decodificación MLA eficiente para GPU Hopper, optimizado para el servicio de secuencias de longitud variable”.
Traducido, es:
“FlashMLA es un núcleo de decodificación MLA eficiente optimizado para las GPU de arquitectura NVIDIA Hopper, específicamente optimizado para escenarios de servicio que procesan secuencias de longitud variable”.
En una palabra:
FlashMLA es un núcleo de decodificación eficiente diseñado por DeepInference para GPU con arquitectura Hopper (como la H800). Al optimizar el cálculo de la atención potencial de múltiples cabezales de secuencias de longitud variable, logra el máximo rendimiento de ancho de banda de memoria de 3000 GB/s y potencia de procesamiento de 580 TFLOPS en la etapa de decodificación, lo que mejora significativamente la eficiencia del razonamiento con contextos largos para modelos grandes.
Algunos internautas dijeron:

Algunas personas ya lo están usando y dicen Pura ingeniería:
Este proyecto pertenece a la ingeniería de optimización y exprime el rendimiento del hardware al máximo límite.
El proyecto está listo para usarse nada más sacarlo de la caja.
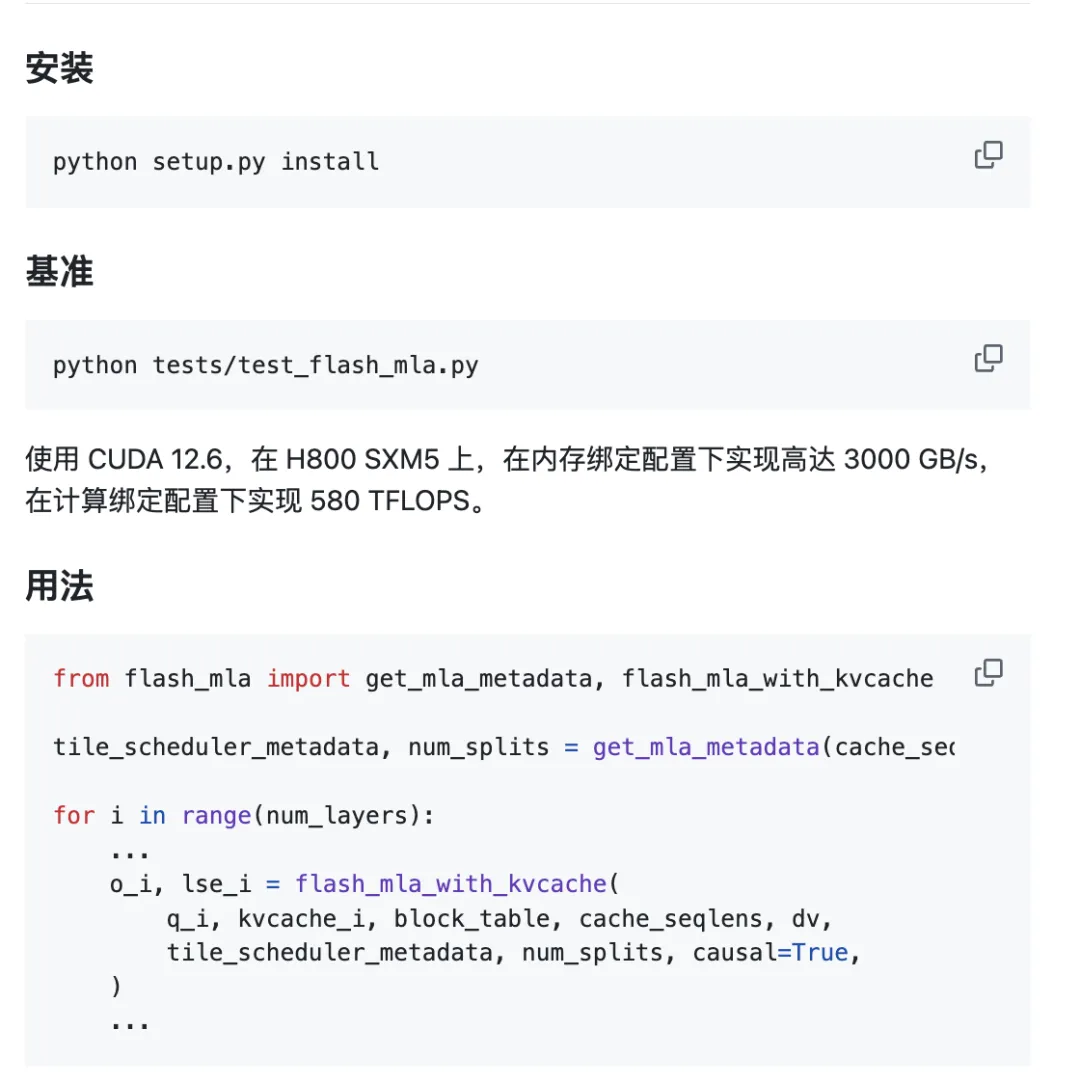
Requisitos ambientales:
- GPU de tolva
- CUDA 12.3 y superior
- PyTorch 2.0 y superior
Al finalizar el proyecto, el funcionario también afirmó que estaba inspirado en los proyectos FlashAttention 2&3 y NVIDIA CUTLASS.

FlashAttention es capaz de lograr una atención rápida y precisa con un uso eficiente de la memoria, y se utiliza en modelos de gran tamaño convencionales. La última versión de tercera generación puede aumentar la tasa de utilización del H100 a 75%.
La velocidad de entrenamiento aumenta entre 1,5 y 2 veces y el rendimiento computacional bajo FP16 es tan alto como 740 TFLOPs/s, alcanzando 75% del rendimiento máximo teórico y haciendo un uso más completo de los recursos computacionales, que anteriormente eran solo 35%.
FlashMLA no solo logra un salto en el rendimiento a través de la optimización a nivel de hardware, sino que también proporciona una solución lista para usar para las prácticas de ingeniería en inferencia de IA, convirtiéndose en un avance tecnológico clave para acelerar la inferencia de modelos grandes.
Hubo una gran revelación el primer día.
¡Estoy esperando con ansias el material de código abierto en los próximos cuatro días!
Como dijo el internauta:

¡La ballena está haciendo olas!
¡DeepSeek es increíble!



