

Eelmisel nädalal teatas DeepSeek, et avab järgmisel nädalal viis projekti:

Netizens ütles: "Seekord on OpenAI tõesti siin."
Just nüüd tuli esimene avatud lähtekoodiga projekt, mis on seotud järelduste kiirendusega, FlashMLA:
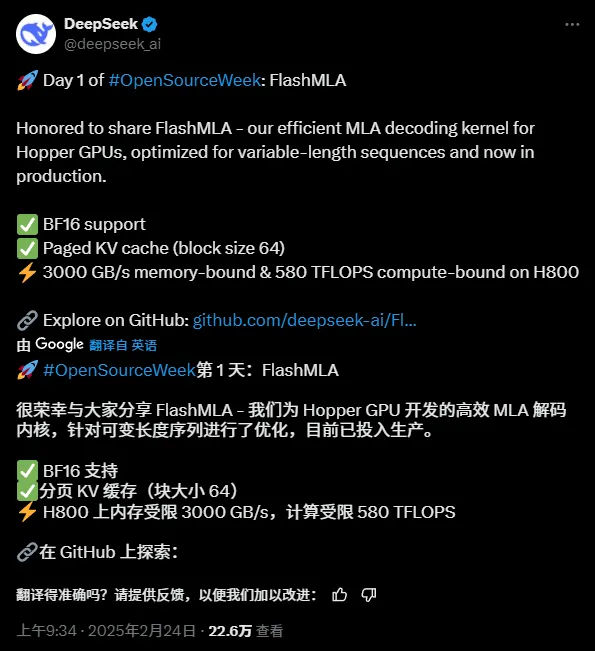
Avatud lähtekoodiga projekti aadress:
See on olnud avatud lähtekoodiga kaks tundi ja Githubil on juba 2,7 000+ tärni:
Projekti põhifunktsioon on:
"FlashMLA on tõhus MLA dekodeerimise tuum Hopperi GPU-de jaoks, mis on optimeeritud muutuva pikkusega jadate teenindamiseks."
Tõlgitud, on küll:
"FlashMLA on tõhus MLA dekodeerimise tuum, mis on optimeeritud NVIDIA Hopperi arhitektuuriga GPU-de jaoks ja mis on spetsiaalselt optimeeritud muutuva pikkusega jadasid töötlevate teenusestsenaariumide jaoks."
Lühidalt:
FlashMLA on tõhus dekodeerimistuum, mille DeepInference on välja töötanud Hopperi arhitektuuriga GPU-de (nt H800) jaoks. Optimeerides muutuva pikkusega jadade mitme peaga potentsiaalse tähelepanu arvutamist, saavutab see 3000 GB/s mälu ribalaiuse ja 580 TFLOPS arvutusvõimsuse dekodeerimisetapis, parandades märkimisväärselt suurte mudelite puhul pikkade kontekstidega arutlemise tõhusust.
Mõned netiinimesed ütlesid:

Mõned inimesed juba kasutavad seda ja nad ütlevad Pure engineering:
See projekt kuulub inseneri optimeerimise ja surub riistvara jõudluse alla piir.
Projekt on karbist välja võttes kasutamiseks valmis.
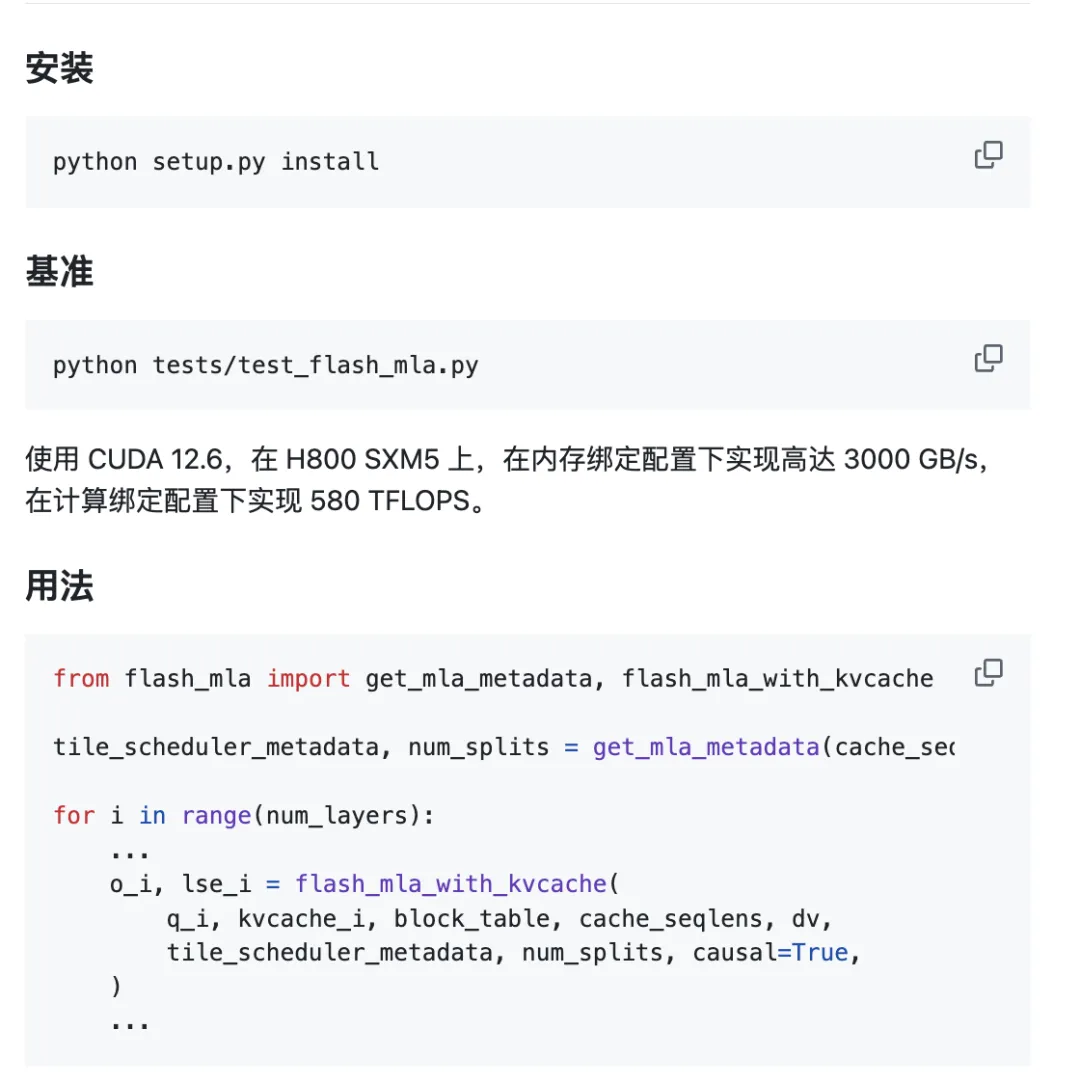
Keskkonnanõuded:
- Punkri GPU
- CUDA 12.3 ja uuemad
- PyTorch 2.0 ja uuemad
Projekti lõpus märkis ametnik ka, et see on inspireeritud projektidest FlashAttention 2&3 ja NVIDIA CUTLASS.

FlashAttention on võimeline saavutama kiiret ja mälusäästlikku täpset tähelepanu ning seda kasutatakse tavalistes suurtes mudelites. Uusim kolmanda põlvkonna versioon võib suurendada H100 kasutusmäära 75%-ni.
Treeningu kiirust suurendatakse 1,5-2 korda ning arvutuslik läbilaskevõime FP16 all on koguni 740 TFLOPs/s, saavutades 75% teoreetilisest maksimaalsest läbilaskevõimest ja kasutades ära arvutusressursse, mis varem oli vaid 35%.
FlashMLA mitte ainult ei saavuta riistvaratasemel optimeerimise kaudu jõudlushüpet, vaid pakub ka valmis lahendust tehisintellekti järeldamise inseneripraktikatele, muutudes peamiseks tehnoloogiliseks läbimurdeks suurte mudelite järelduste tegemise kiirendamisel.
Esimesel päeval oli nii suur paljastamine.
Ootan huviga avatud lähtekoodiga kraami järgmise nelja päeva jooksul!
Nagu netimees ütles:

Vaal lööb laineid!
DeepSeek on suurepärane!


