

Viime viikolla DeepSeek ilmoitti avaavansa viisi projektia ensi viikolla:

Netizens sanoi: "Tällä kertaa OpenAI on todella täällä."
Juuri nyt tuli ensimmäinen avoimen lähdekoodin projekti, joka liittyy päättelykiihdytykseen, FlashMLA:
Avoimen lähdekoodin projektin osoite:
Se on ollut avoimen lähdekoodin kaksi tuntia, ja Githubilla on jo yli 2,7 000 tähteä:
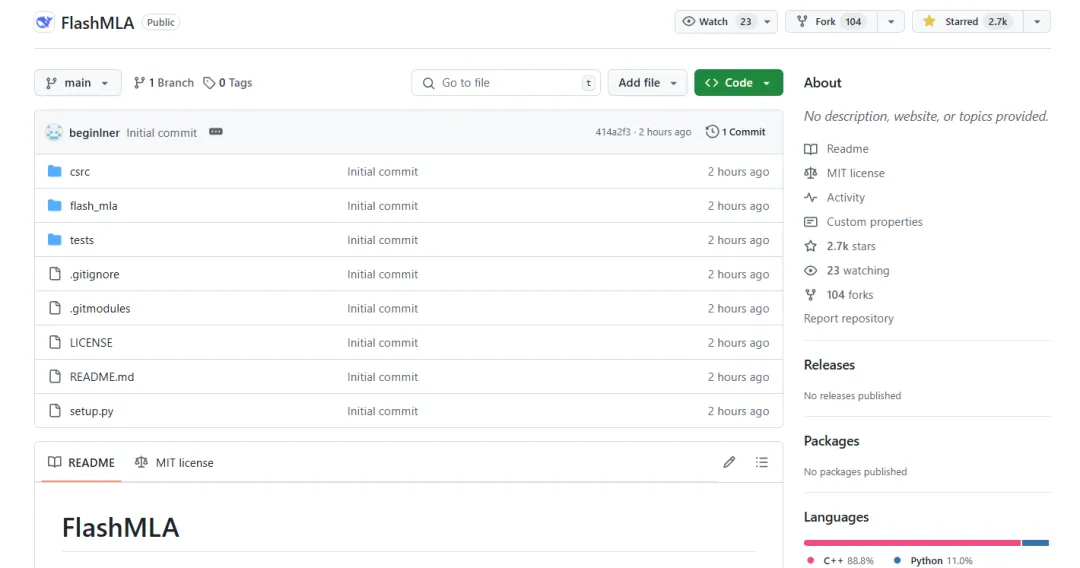
Projektin ydintoiminto on:
"FlashMLA on tehokas MLA-dekoodausydin Hopperin GPU:ille, joka on optimoitu vaihtuvan pituisten sekvenssien palvelemiseen."
Käännettynä se on:
"FlashMLA on tehokas MLA-dekoodausydin, joka on optimoitu NVIDIA Hopper -arkkitehtuurin GPU:ille, erityisesti optimoitu palveluskenaarioihin, jotka käsittelevät muuttuvan pituisia sekvenssejä."
Pähkinänkuoressa:
FlashMLA on tehokas dekoodausydin, jonka DeepInference on suunnitellut Hopper-arkkitehtuurin GPU:ille (kuten H800). Optimoimalla vaihtelevan pituisten sekvenssien monipään potentiaalisen huomion laskennan, se saavuttaa äärimmäisen suorituskyvyn 3000 Gt/s muistin kaistanleveydellä ja 580 TFLOPS:n laskentateholla dekoodausvaiheessa, mikä parantaa merkittävästi päättelyn tehokkuutta pitkillä yhteyksillä suurissa malleissa.
Jotkut nettimiehet sanoivat:

Jotkut ihmiset käyttävät sitä jo, ja he sanovat Pure engineering:
Tämä projekti kuuluu suunnittelun optimointiin ja puristaa laitteiston suorituskyvyn rajoittaa.
Projekti on heti käyttövalmis.
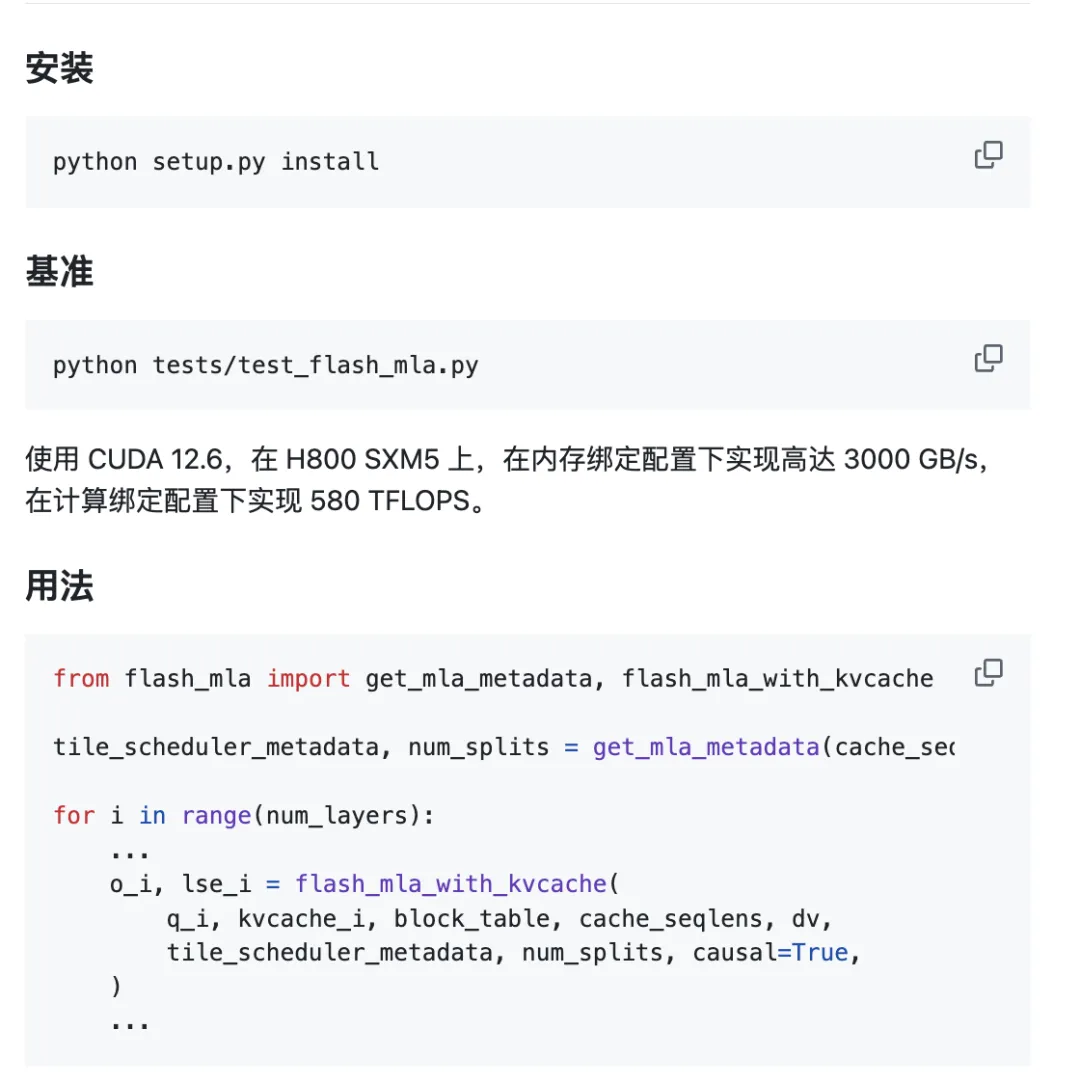
Ympäristövaatimukset:
- Hopper GPU
- CUDA 12.3 ja uudemmat
- PyTorch 2.0 ja uudemmat
Projektin lopussa virkamies totesi myös, että se oli saanut inspiraationsa FlashAttention 2&3- ja NVIDIA CUTLASS -projekteista.

FlashAttention pystyy saavuttamaan nopean ja muistitehokkaan tarkan huomion, ja sitä käytetään valtavirran suurissa malleissa. Uusin kolmannen sukupolven versio voi nostaa H100:n käyttöastetta 75%:hen.
Harjoittelun nopeus kasvaa 1,5-2-kertaiseksi ja FP16:n laskennallinen suorituskyky on peräti 740 TFLOPs/s, saavuttaen 75% teoreettisesta maksimista ja hyödyntäen paremmin laskentaresursseja, mikä aiemmin oli vain 35%.
FlashMLA ei vain saavuta harppausta suorituskyvyssä laitteistotason optimoinnin avulla, vaan tarjoaa myös valmiin ratkaisun tekoälyn päättelyn suunnittelukäytäntöihin, ja siitä tulee keskeinen tekninen läpimurto suurten mallien päättelyn nopeuttamisessa.
Ensimmäisenä päivänä oli suuri paljastus.
Odotan innolla avoimen lähdekoodin juttuja seuraavan neljän päivän aikana!
Kuten nettimies sanoi:

Valas tekee aaltoja!
DeepSeek on mahtava!



