

지난 주 DeepSeek는 다음 주에 5개 프로젝트를 오픈 소스로 공개한다고 발표했습니다.

네티즌들은 "이번엔 OpenAI가 정말 왔구나"라고 입을 모았다.
방금 추론 가속과 관련된 첫 번째 오픈소스 프로젝트인 FlashMLA가 나왔습니다.
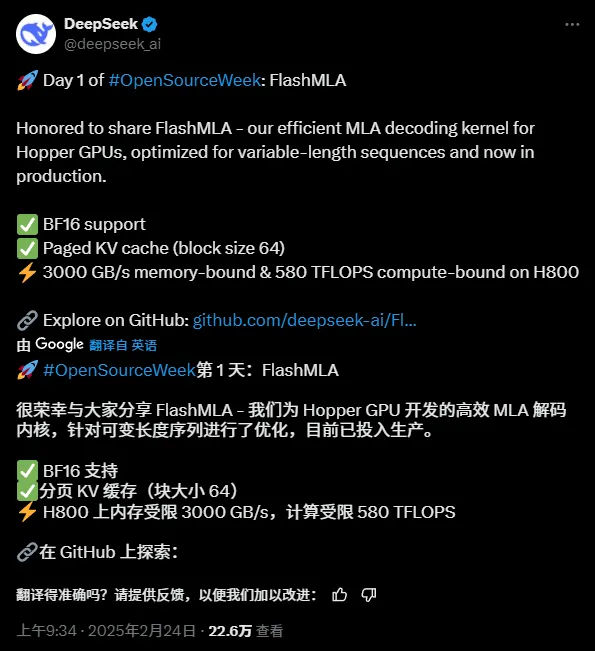
오픈소스 프로젝트 주소:
오픈 소스로 공개된 지 2시간이 지났고 Github에는 이미 2.7k개 이상의 별이 있습니다.
이 프로젝트의 핵심 기능은 다음과 같습니다.
“FlashMLA는 가변 길이 시퀀스 제공을 위해 최적화된 Hopper GPU용 효율적인 MLA 디코딩 커널입니다.”
번역하면 다음과 같습니다:
“FlashMLA는 NVIDIA Hopper 아키텍처 GPU에 최적화된 효율적인 MLA 디코딩 커널로, 특히 가변 길이 시퀀스를 처리하는 서비스 시나리오에 최적화되었습니다.”
요약해서 말하면:
FlashMLA는 DeepInference가 Hopper 아키텍처 GPU(예: H800)를 위해 설계한 효율적인 디코딩 코어입니다. 가변 길이 시퀀스의 멀티헤드 잠재적 어텐션 계산을 최적화하여 디코딩 단계에서 3000GB/s 메모리 대역폭과 580TFLOPS 컴퓨팅 파워의 궁극적인 성능을 달성하여 대규모 모델에 대한 긴 컨텍스트 추론의 효율성을 크게 향상시킵니다.
일부 네티즌들은 다음과 같이 말했다.

이미 이를 사용하고 있는 사람들이 있는데, 그들은 순수 엔지니어링이라고 말합니다.
이 프로젝트는 엔지니어링 최적화에 속합니다. 하드웨어 성능을 압축합니다. 한계.
이 프로젝트는 바로 사용할 수 있습니다.
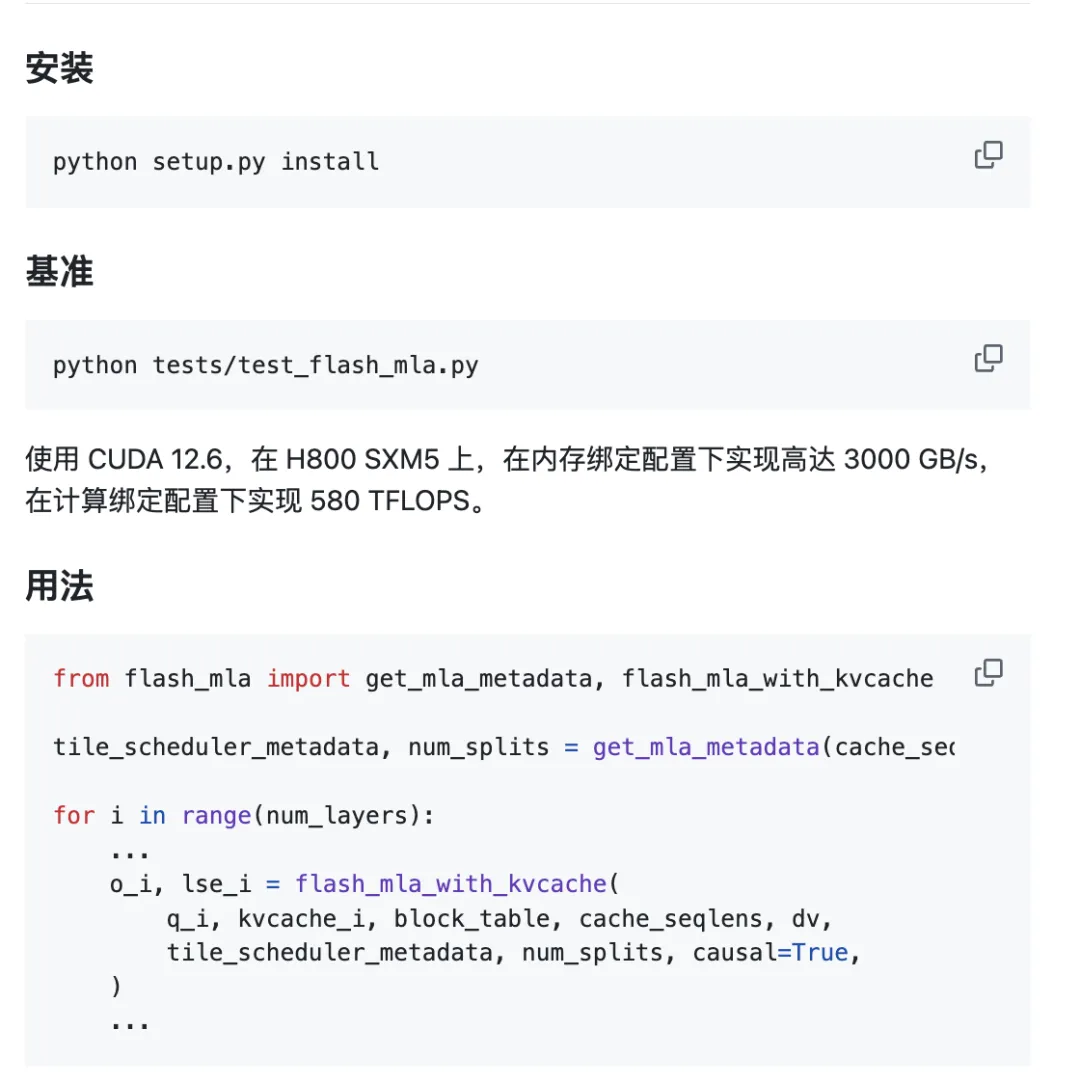
환경 요구 사항:
- 호퍼 GPU
- CUDA 12.3 이상
- PyTorch 2.0 이상
프로젝트가 끝난 후 관계자는 이것이 FlashAttention 2&3과 NVIDIA CUTLASS 프로젝트에서 영감을 받았다고 밝혔습니다.

FlashAttention은 빠르고 메모리 효율적인 정밀 주의를 달성할 수 있으며 주류 대형 모델에 사용됩니다. 최신 3세대 버전은 H100의 활용률을 75%로 높일 수 있습니다.
학습 속도가 1.5-2배 빨라지고, FP16에서의 연산 처리량은 최대 740 TFLOPs/s로 높아져, 이론적인 최대 처리량의 75%에 도달하고, 이전에 35%에 불과했던 컴퓨팅 리소스를 더욱 충분히 활용할 수 있습니다.
플래시MLA 하드웨어 수준의 최적화를 통해 성능을 획기적으로 향상시킬 뿐만 아니라, AI 추론의 엔지니어링 실무에 대한 획기적인 솔루션을 제공하여 대규모 모델의 추론을 가속화하는 핵심 기술적 혁신이 되었습니다.
첫날에 정말 큰 공개가 있었죠.
저는 앞으로 4일간의 오픈소스에 대한 내용을 기대하고 있습니다!
네티즌은 이렇게 말했습니다.

고래가 파도를 일으키고 있어요!
DeepSeek는 정말 멋지네요!




