

Минатата недела, DeepSeek објави дека следната недела ќе отвори пет проекти со отворен код:

Нетизените рекоа: „Овој пат, OpenAI е навистина тука“.
Токму сега, дојде првиот проект со отворен код, поврзан со забрзувањето на заклучоците, FlashMLA:
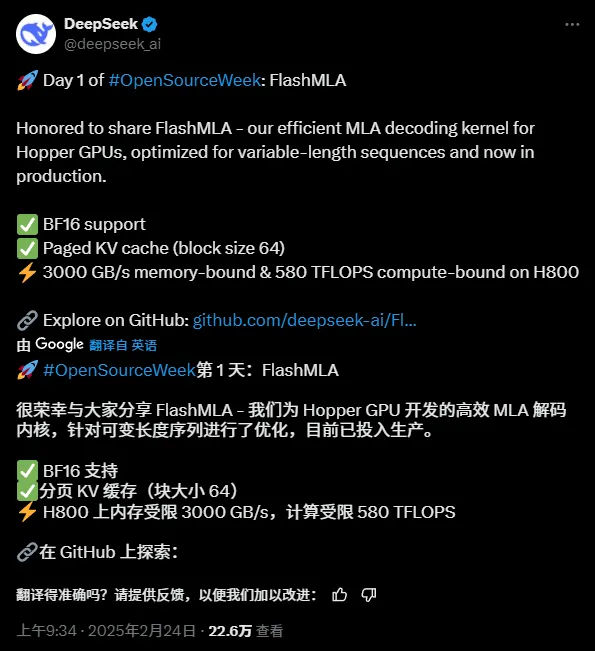
Адреса на проектот со отворен код:
Тој е со отворен код веќе два часа, а Github веќе има 2,7k+ ѕвезди:
Основната функција на проектот е:
„FlashMLA е ефикасен кернел за декодирање MLA за графички процесори на Hopper, оптимизиран за сервирање секвенци со променлива должина“.
Во превод, тоа е:
„FlashMLA е ефикасен кернел за декодирање MLA оптимизиран за графички процесори на архитектурата NVIDIA Hopper, специјално оптимизиран за сценарија за услуги што обработуваат секвенци со променлива должина“.
Накратко:
FlashMLA е ефикасно јадро за декодирање дизајнирано од DeepInference за графички процесори со архитектура Hopper (како што е H800). Со оптимизирање на пресметувањето на потенцијалното внимание на повеќе глави на секвенците со променлива должина, се постигнува крајна изведба од 3000 GB/s пропусен опсег на меморија и 580 TFLOPS компјутерска моќ во фазата на декодирање, што значително ја подобрува ефикасноста на расудувањето со долги контексти за големи модели.
Некои корисници на Интернет рекоа:

Некои луѓе веќе го користат, и велат чисто инженерство:
Овој проект припаѓа на инженерска оптимизација и ги стиска перформансите на хардверот на ограничување.
Проектот е подготвен за употреба надвор од кутијата.
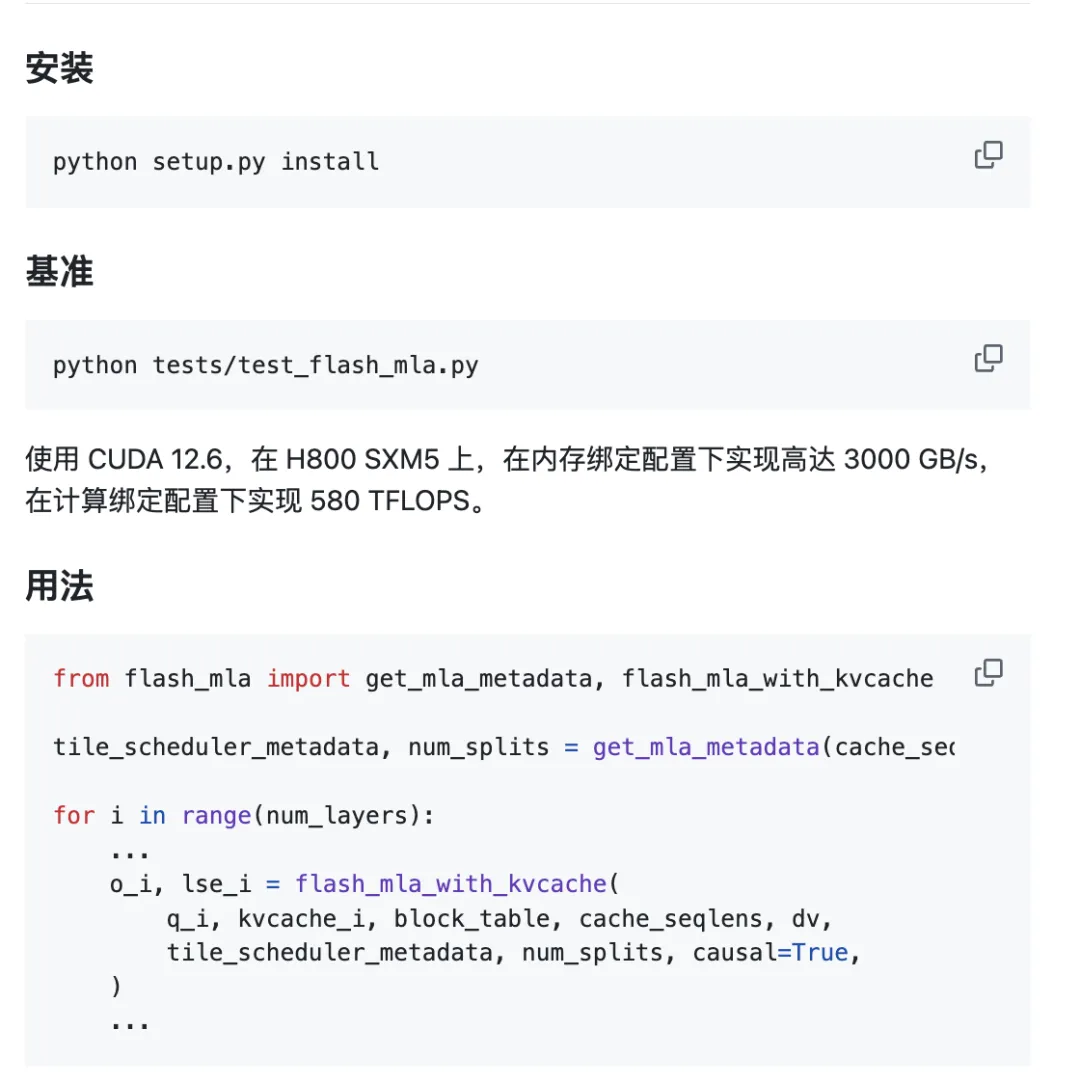
Барања за животната средина:
- Хопер графички процесор
- CUDA 12.3 и погоре
- PyTorch 2.0 и погоре
На крајот на проектот, службеникот исто така изјави дека е инспириран од проектите FlashAttention 2&3 и NVIDIA CUTLASS.

FlashAttention е способен да постигне брзо и ефикасно прецизно внимание за меморија и се користи во главните големи модели. Најновата верзија од третата генерација може да ја зголеми стапката на искористеност на H100 на 75%.
Брзината на обука е зголемена за 1,5-2 пати, а пресметковната пропусност под FP16 е висока до 740 TFLOPs/s, достигнувајќи 75% од теоретската максимална пропусност и целосно искористувајќи ги компјутерските ресурси, што претходно беше само 35%.
FlashMLA не само што постигнува скок во перформансите преку оптимизација на ниво на хардвер, туку обезбедува и надворешно решение за инженерски практики во заклучоците за вештачка интелигенција, станувајќи клучен технолошки пробив во забрзувањето на заклучоците на големите модели.
Имаше толку големо откривање на првиот ден.
Со нетрпение ги очекувам работите со отворен код во следните четири дена!
Како што рече нетизенот:

Китот прави бранови!
DeepSeek е одличен!


