

Na semana passada, a DeepSeek anunciou que disponibilizaria cinco projetos de código aberto na próxima semana:

Os internautas disseram: “Desta vez, o OpenAI realmente chegou”.
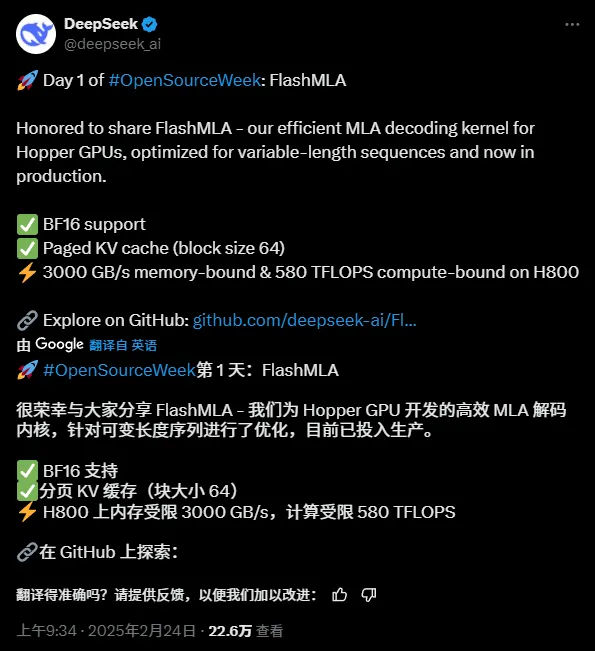
Agora mesmo surgiu o primeiro projeto de código aberto relacionado à aceleração de inferência, o FlashMLA:
Endereço do projeto de código aberto:
O código-fonte está aberto há duas horas e o Github já tem mais de 2,7 mil estrelas:
A função principal do projeto é:
“FlashMLA é um kernel de decodificação MLA eficiente para GPUs Hopper, otimizado para servir sequências de comprimento variável.”
Traduzido, é:
“FlashMLA é um kernel de decodificação MLA eficiente otimizado para GPUs de arquitetura NVIDIA Hopper, especificamente otimizado para cenários de serviço que processam sequências de comprimento variável.”
Em poucas palavras:
FlashMLA é um núcleo de decodificação eficiente projetado pela DeepInference para GPUs de arquitetura Hopper (como o H800). Ao otimizar o cálculo de atenção potencial multicabeça de sequências de comprimento variável, ele atinge o desempenho máximo de largura de banda de memória de 3000 GB/s e poder de computação de 580 TFLOPS no estágio de decodificação, melhorando significativamente a eficiência do raciocínio com contextos longos para modelos grandes.
Alguns internautas disseram:

Algumas pessoas já estão usando e dizem Engenharia pura:
Este projeto pertence à otimização de engenharia e reduz o desempenho do hardware para o limite.
O projeto está pronto para uso imediato.
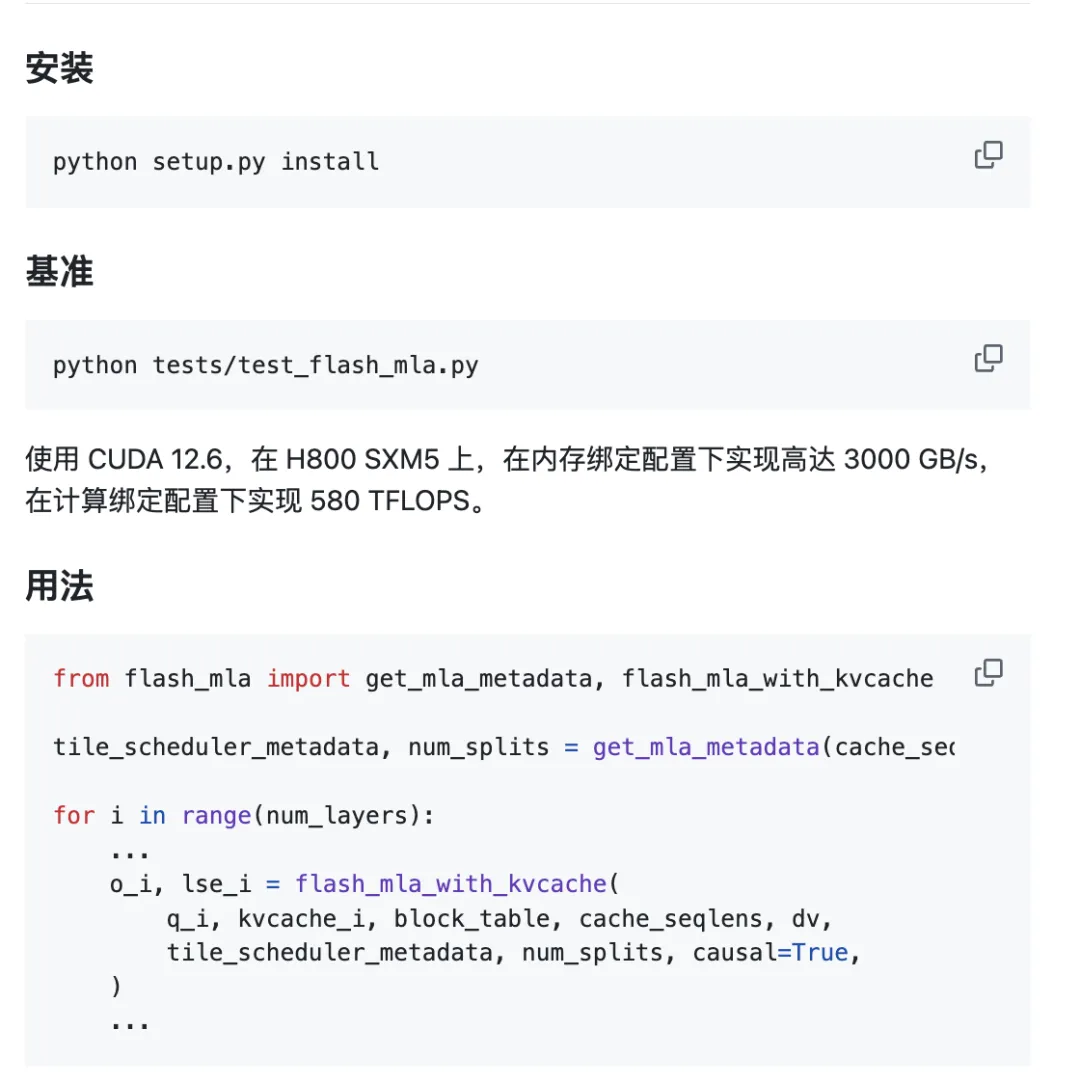
Requisitos ambientais:
- GPU Hopper
- CUDA 12.3 e superior
- PyTorch 2.0 e superior
Ao final do projeto, o responsável afirmou ainda que ele foi inspirado nos projetos FlashAttention 2&3 e NVIDIA CUTLASS.

O FlashAttention é capaz de atingir atenção precisa, rápida e com eficiência de memória, e é usado em modelos grandes convencionais. A versão mais recente de terceira geração pode aumentar a taxa de utilização do H100 para 75%.
A velocidade de treinamento é aumentada em 1,5-2 vezes, e o rendimento computacional sob FP16 é tão alto quanto 740 TFLOPs/s, atingindo 75% do rendimento máximo teórico e fazendo uso mais completo dos recursos de computação, que antes eram de apenas 35%.
FlashMLA não apenas alcança um salto no desempenho por meio da otimização em nível de hardware, mas também fornece uma solução pronta para uso para práticas de engenharia em inferência de IA, tornando-se um avanço tecnológico fundamental na aceleração da inferência de grandes modelos.
Houve uma grande revelação no primeiro dia.
Estou ansioso pelas novidades de código aberto nos próximos quatro dias!
Como disse o internauta:

A baleia está fazendo ondas!
DeepSeek é incrível!



