

Tuần trước, DeepSeek đã thông báo rằng họ sẽ mở mã nguồn năm dự án vào tuần tới:

Cư dân mạng cho biết, “Lần này, OpenAI thực sự đã xuất hiện”.
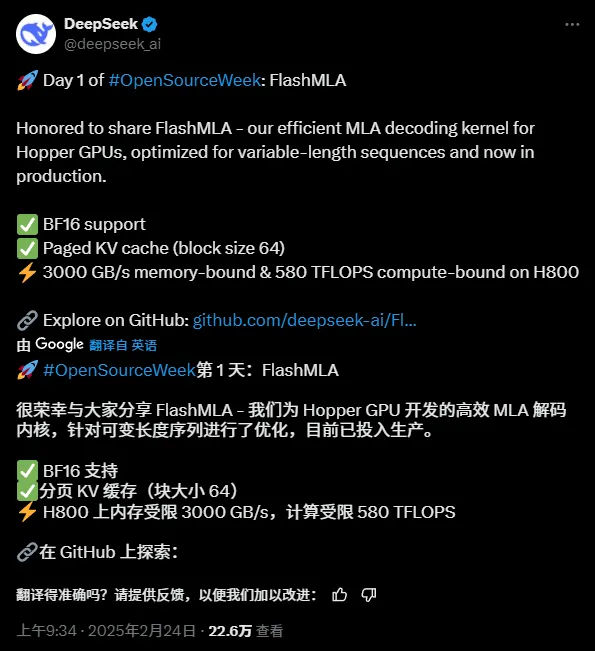
Vừa rồi, dự án nguồn mở đầu tiên liên quan đến tăng tốc suy luận, FlashMLA đã ra đời:
Địa chỉ dự án nguồn mở:
Nó đã là mã nguồn mở trong hai giờ và Github đã có hơn 2,7 nghìn sao:
Chức năng cốt lõi của dự án là:
“FlashMLA là một hạt nhân giải mã MLA hiệu quả cho GPU Hopper, được tối ưu hóa để phục vụ các chuỗi có độ dài thay đổi.”
Được dịch là:
“FlashMLA là một hạt nhân giải mã MLA hiệu quả được tối ưu hóa cho GPU kiến trúc NVIDIA Hopper, được tối ưu hóa cụ thể cho các tình huống dịch vụ xử lý chuỗi có độ dài thay đổi.”
Nói tóm lại:
FlashMLA là lõi giải mã hiệu quả được DeepInference thiết kế cho GPU kiến trúc Hopper (như H800). Bằng cách tối ưu hóa tính toán sự chú ý tiềm năng nhiều đầu của các chuỗi có độ dài thay đổi, nó đạt được hiệu suất tối đa là băng thông bộ nhớ 3000GB/giây và sức mạnh tính toán 580TFLOPS trong giai đoạn giải mã, cải thiện đáng kể hiệu quả suy luận với các ngữ cảnh dài cho các mô hình lớn.
Một số cư dân mạng cho biết:

Một số người đã sử dụng nó và họ nói Kỹ thuật thuần túy:
Dự án này thuộc về kỹ thuật tối ưu hóa và ép hiệu suất phần cứng đến mức giới hạn.
Dự án đã sẵn sàng để sử dụng ngay.
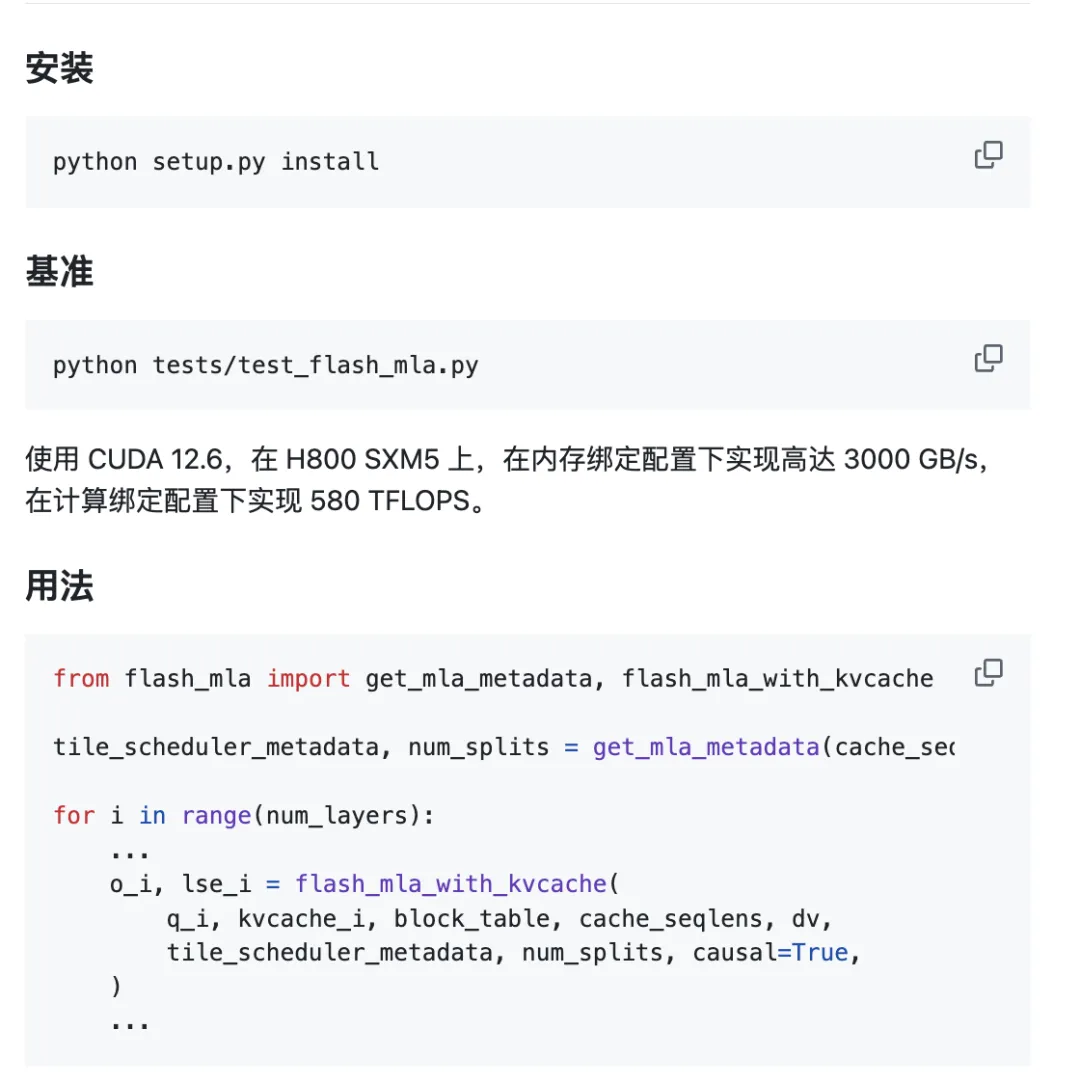
Yêu cầu về môi trường:
- GPU phễu
- CUDA 12.3 trở lên
- PyTorch 2.0 trở lên
Khi kết thúc dự án, vị quan chức này cũng tuyên bố rằng dự án được lấy cảm hứng từ các dự án FlashAttention 2&3 và NVIDIA CUTLASS.

FlashAttention có khả năng đạt được sự chú ý chính xác nhanh chóng và hiệu quả về bộ nhớ, và được sử dụng trong các mô hình lớn chính thống. Phiên bản thế hệ thứ ba mới nhất có thể tăng tỷ lệ sử dụng của H100 lên 75%.
Tốc độ đào tạo được tăng lên 1,5-2 lần và thông lượng tính toán theo FP16 cao tới 740 TFLOPs/giây, đạt 75% thông lượng tối đa theo lý thuyết và tận dụng đầy đủ hơn các tài nguyên tính toán trước đây chỉ là 35%.
FlashMLA không chỉ đạt được bước nhảy vọt về hiệu suất thông qua tối ưu hóa ở cấp độ phần cứng mà còn cung cấp giải pháp sáng tạo cho các hoạt động kỹ thuật trong suy luận AI, trở thành bước đột phá công nghệ quan trọng trong việc tăng tốc suy luận các mô hình lớn.
Có một sự tiết lộ lớn như vậy vào ngày đầu tiên.
Tôi rất mong chờ những thông tin về mã nguồn mở trong bốn ngày tới!
Như cư dân mạng đã nói:

Cá voi đang tạo ra sóng!
DeepSeek thật tuyệt vời!


