

Την περασμένη εβδομάδα, το DeepSeek ανακοίνωσε ότι θα επρόκειτο για πέντε έργα ανοιχτού κώδικα την επόμενη εβδομάδα:

Οι χρήστες του Διαδικτύου είπαν: «Αυτή τη φορά, το OpenAI είναι πραγματικά εδώ».
Μόλις τώρα, ήρθε το πρώτο έργο ανοιχτού κώδικα, που σχετίζεται με την επιτάχυνση συμπερασμάτων, το FlashMLA:
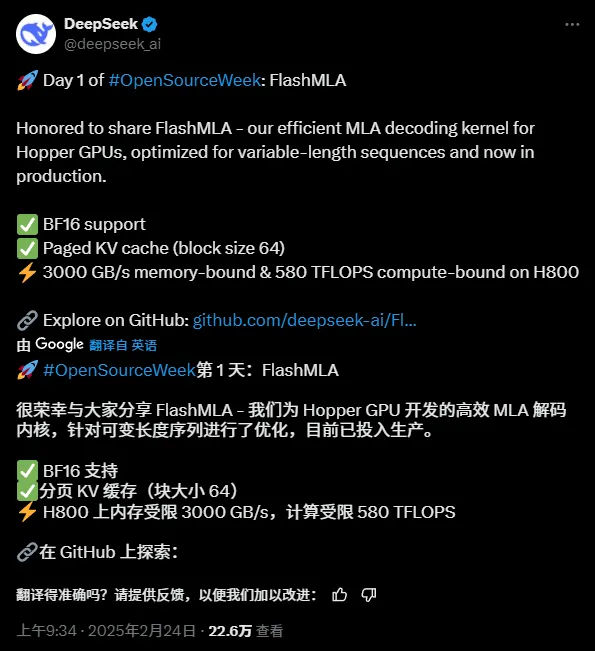
Διεύθυνση έργου ανοιχτού κώδικα:
Είναι ανοιχτού κώδικα εδώ και δύο ώρες και το Github έχει ήδη 2,7k+ αστέρια:
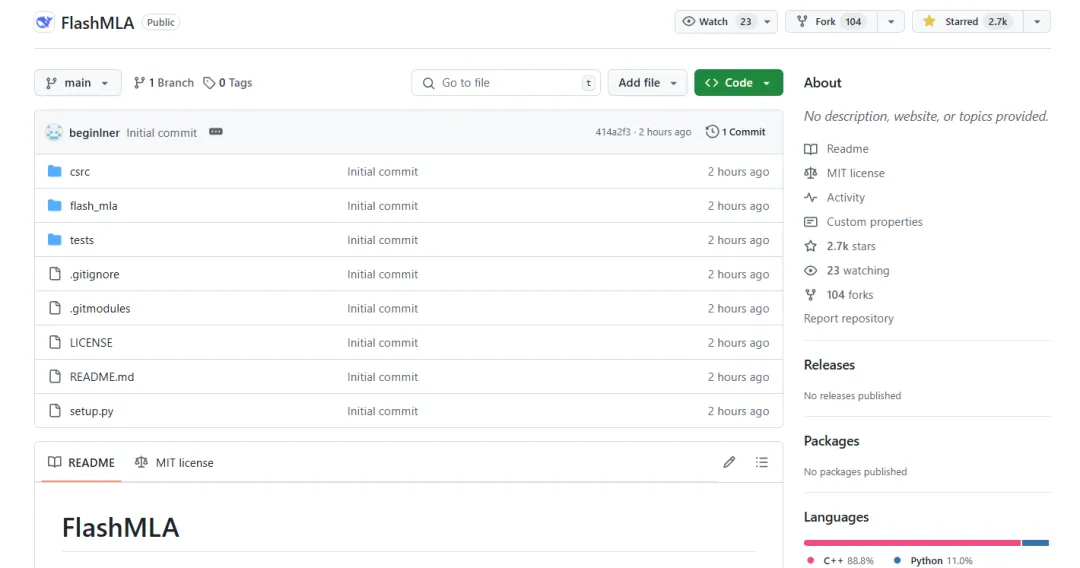
Η βασική λειτουργία του έργου είναι:
"Το FlashMLA είναι ένας αποτελεσματικός πυρήνας αποκωδικοποίησης MLA για Hopper GPU, βελτιστοποιημένος για την προβολή ακολουθιών μεταβλητού μήκους."
Μεταφρασμένο, είναι:
"Το FlashMLA είναι ένας αποτελεσματικός πυρήνας αποκωδικοποίησης MLA βελτιστοποιημένος για GPU αρχιτεκτονικής NVIDIA Hopper, ειδικά βελτιστοποιημένος για σενάρια υπηρεσιών που επεξεργάζονται ακολουθίες μεταβλητού μήκους."
Με λίγα λόγια:
Το FlashMLA είναι ένας αποτελεσματικός πυρήνας αποκωδικοποίησης που σχεδιάστηκε από την DeepInference για GPU με αρχιτεκτονική Hopper (όπως το H800). Βελτιστοποιώντας τον υπολογισμό δυναμικής προσοχής πολλαπλών κεφαλών των ακολουθιών μεταβλητού μήκους, επιτυγχάνει την απόλυτη απόδοση εύρους ζώνης μνήμης 3000 GB/s και υπολογιστική ισχύ 580 TFLOPS στο στάδιο της αποκωδικοποίησης, βελτιώνοντας σημαντικά την αποτελεσματικότητα της συλλογιστικής με μεγάλα πλαίσια για μεγάλα μοντέλα.
Κάποιοι χρήστες του Διαδικτύου είπαν:

Μερικοί άνθρωποι το χρησιμοποιούν ήδη και λένε Pure engineering:
Αυτό το έργο ανήκει στη μηχανική βελτιστοποίηση και συμπιέζει την απόδοση του υλικού στο όριο.
Το έργο είναι έτοιμο για χρήση εκτός συσκευασίας.
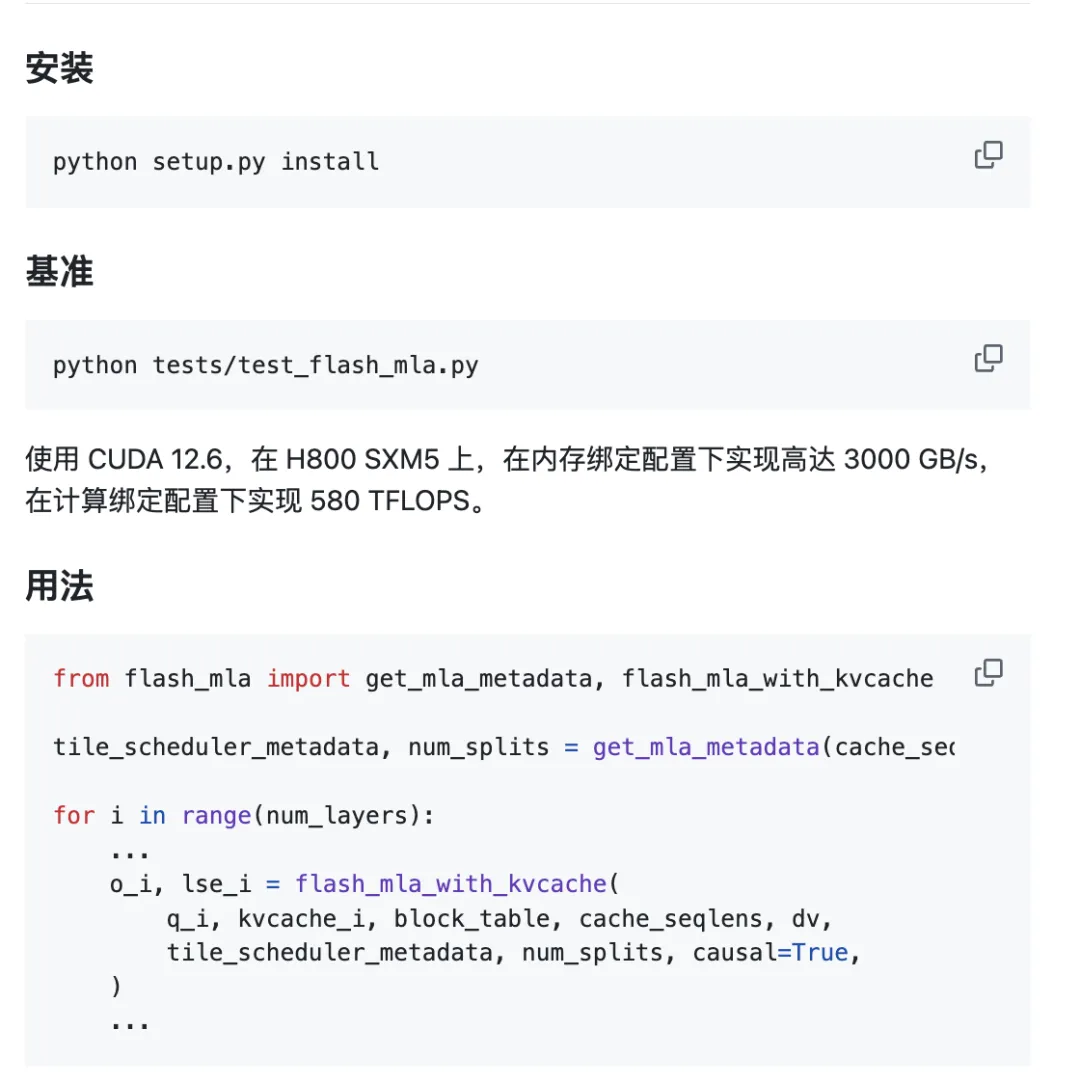
Περιβαλλοντικές απαιτήσεις:
- GPU Hopper
- CUDA 12.3 και άνω
- PyTorch 2.0 και νεότερη έκδοση
Στο τέλος του έργου, ο αξιωματούχος δήλωσε επίσης ότι εμπνεύστηκε από τα έργα FlashAttention 2&3 και NVIDIA CUTLASS.

Το FlashAttention είναι ικανό να επιτύχει γρήγορη και αποδοτική από πλευράς μνήμης ακριβή προσοχή και χρησιμοποιείται σε μεγάλα μεγάλα μοντέλα. Η τελευταία έκδοση τρίτης γενιάς μπορεί να αυξήσει το ποσοστό χρήσης του H100 σε 75%.
Η ταχύτητα εκπαίδευσης αυξάνεται κατά 1,5-2 φορές και η υπολογιστική απόδοση στο FP16 φτάνει τα 740 TFLOPs/s, φτάνοντας τα 75% της θεωρητικής μέγιστης απόδοσης και κάνοντας πληρέστερη χρήση των υπολογιστικών πόρων, που προηγουμένως ήταν μόνο 35%.
FlashMLA όχι μόνο επιτυγχάνει ένα άλμα στην απόδοση μέσω της βελτιστοποίησης σε επίπεδο υλικού, αλλά παρέχει επίσης μια ολοκληρωμένη λύση για μηχανικές πρακτικές στην εξαγωγή συμπερασμάτων τεχνητής νοημοσύνης, καθιστώντας μια βασική τεχνολογική ανακάλυψη στην επιτάχυνση της εξαγωγής συμπερασμάτων μεγάλων μοντέλων.
Υπήρχε μια τόσο μεγάλη αποκάλυψη την πρώτη μέρα.
Ανυπομονώ για το υλικό ανοιχτού κώδικα τις επόμενες τέσσερις ημέρες!
Όπως είπε ο διαδικτυακός χρήστης:

Η φάλαινα κάνει κύματα!
Το DeepSeek είναι φοβερό!



