

Minggu lepas, DeepSeek mengumumkan bahawa ia akan membuka lima projek sumber minggu depan:

Netizen berkata, "Kali ini, OpenAI benar-benar di sini."
Tadi, projek sumber terbuka pertama datang, berkaitan dengan pecutan inferens, FlashMLA:
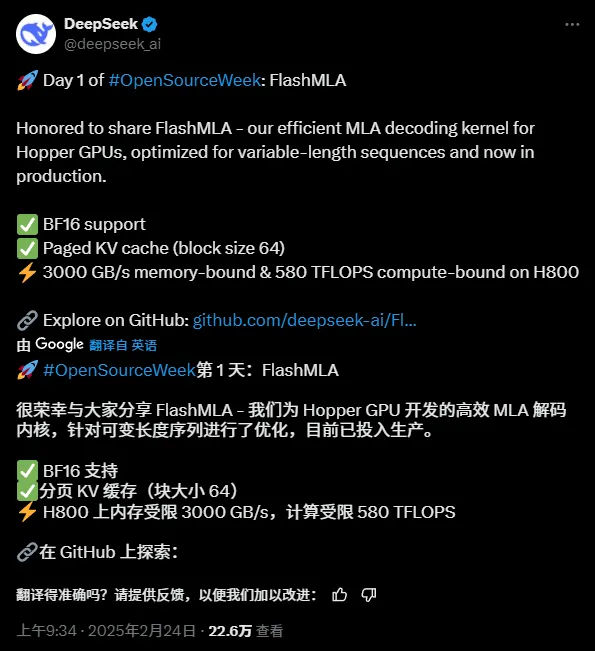
Alamat projek sumber terbuka:
Ia telah menjadi sumber terbuka selama dua jam, dan Github sudah mempunyai 2.7k+ bintang:
Fungsi teras projek ialah:
"FlashMLA ialah kernel penyahkodan MLA yang cekap untuk GPU Hopper, dioptimumkan untuk penyajian jujukan panjang berubah-ubah."
Diterjemah, ia adalah:
"FlashMLA ialah kernel penyahkodan MLA yang cekap yang dioptimumkan untuk GPU seni bina NVIDIA Hopper, dioptimumkan khusus untuk senario perkhidmatan yang memproses urutan panjang berubah-ubah."
Secara ringkasnya:
FlashMLA ialah teras penyahkodan cekap yang direka oleh DeepInference untuk GPU seni bina Hopper (seperti H800). Dengan mengoptimumkan pengiraan perhatian berpotensi berbilang kepala bagi jujukan panjang berubah-ubah, ia mencapai prestasi muktamad lebar jalur memori 3000GB/s dan kuasa pengkomputeran 580TFLOPS dalam peringkat penyahkodan, meningkatkan kecekapan penaakulan dengan konteks yang panjang untuk model besar dengan ketara.
Beberapa netizen berkata:

Sesetengah orang sudah menggunakannya, dan mereka berkata Kejuruteraan tulen:
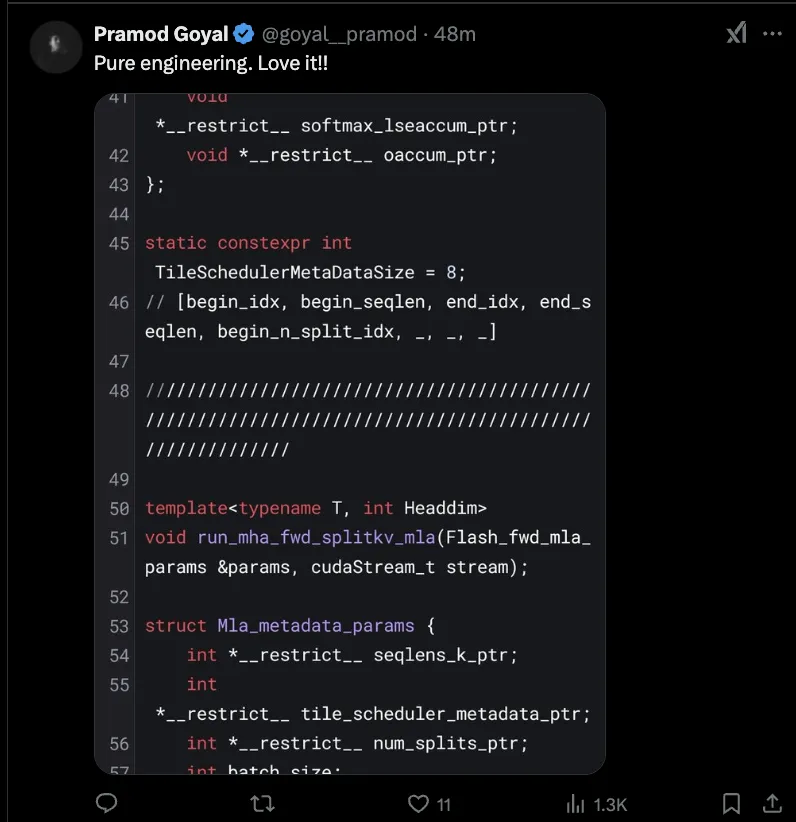
Projek ini tergolong dalam pengoptimuman kejuruteraan dan memerah prestasi perkakasan kepada had.
Projek sedia untuk digunakan di luar kotak.
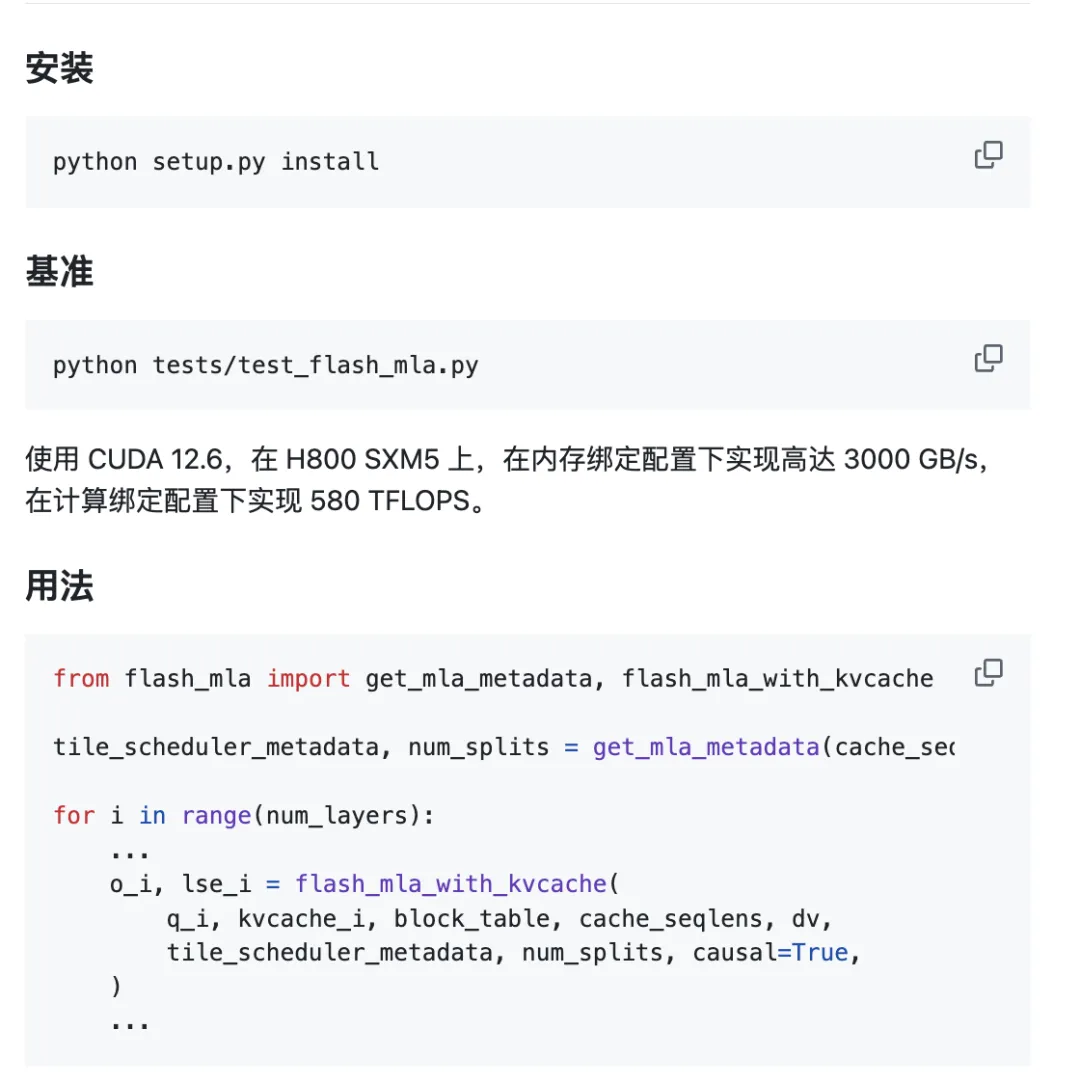
Keperluan persekitaran:
- GPU Hopper
- CUDA 12.3 dan ke atas
- PyTorch 2.0 dan ke atas
Pada akhir projek, pegawai itu juga menyatakan bahawa ia diilhamkan oleh projek FlashAttention 2&3 dan NVIDIA CUTLASS.

FlashAttention mampu mencapai perhatian tepat yang cepat dan cekap memori, dan digunakan dalam model besar arus perdana. Versi generasi ketiga terkini boleh meningkatkan kadar penggunaan H100 kepada 75%.
Kelajuan latihan ditingkatkan sebanyak 1.5-2 kali, dan daya pengiraan di bawah FP16 adalah setinggi 740 TFLOPs/s, mencapai 75% daripada daya pemprosesan maksimum teori dan menggunakan lebih banyak sumber pengkomputeran, yang sebelum ini hanya 35%.
FlashMLA bukan sahaja mencapai lonjakan prestasi melalui pengoptimuman peringkat perkakasan, tetapi juga menyediakan penyelesaian luar biasa untuk amalan kejuruteraan dalam inferens AI, menjadi penemuan teknologi utama dalam mempercepatkan inferens model besar.
Terdapat pendedahan yang begitu besar pada hari pertama.
Saya tidak sabar-sabar untuk bahan sumber terbuka dalam empat hari akan datang!
Bak kata netizen:

Ikan paus membuat ombak!
DeepSeek adalah hebat!


